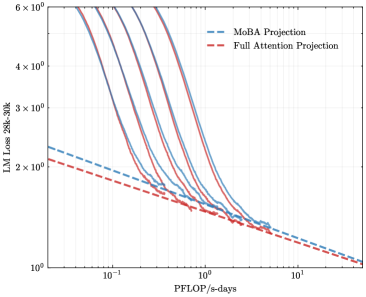
## Line Graph: LM Loss vs. PFLOP/s-days for MoBA and Full Attention Projections
### Overview
The image is a logarithmic line graph comparing the loss reduction of two computational methods (MoBA Projection and Full Attention Projection) as a function of computational resources (PFLOP/s-days). The y-axis represents loss magnitude (10⁰ to 6×10⁰), and the x-axis represents computational scale (10⁻¹ to 10¹). Two data series are plotted: blue dashed lines for MoBA Projection and red dashed lines for Full Attention Projection.
### Components/Axes
- **Y-Axis**: "LM Loss 28k-30k" (logarithmic scale: 10⁰ to 6×10⁰).
- **X-Axis**: "PFLOP/s-days" (logarithmic scale: 10⁻¹ to 10¹).
- **Legend**: Located in the top-right corner, with:
- Blue dashed line: MoBA Projection.
- Red dashed line: Full Attention Projection.
### Detailed Analysis
- **MoBA Projection (Blue Dashed)**:
- Starts at ~2.5×10⁰ loss at 10⁻¹ PFLOP/s-days.
- Decreases sharply to ~1.2×10⁰ at 10⁰ PFLOP/s-days.
- Further reduces to ~0.8×10⁰ at 10¹ PFLOP/s-days.
- **Full Attention Projection (Red Dashed)**:
- Begins at ~2.0×10⁰ loss at 10⁻¹ PFLOP/s-days.
- Drops to ~1.0×10⁰ at 10⁰ PFLOP/s-days.
- Reaches ~0.7×10⁰ at 10¹ PFLOP/s-days.
- **Trends**:
- Both lines exhibit exponential decay, with steeper declines at lower computational scales.
- MoBA Projection maintains a slight lead in loss reduction across all scales but converges with Full Attention Projection at higher PFLOP/s-days (~10¹).
### Key Observations
1. **Convergence**: The two methods' performance gaps narrow significantly as computational resources increase, suggesting diminishing returns on loss reduction beyond ~10⁰ PFLOP/s-days.
2. **Initial Efficiency**: MoBA Projection achieves lower loss than Full Attention Projection at lower computational scales (10⁻¹ to 10⁰ PFLOP/s-days).
3. **Logarithmic Scale Impact**: The logarithmic axes emphasize relative changes, making early-stage improvements appear more pronounced.
### Interpretation
The graph demonstrates that MoBA Projection is more efficient than Full Attention Projection in reducing loss at lower computational scales. However, as resources scale to 10¹ PFLOP/s-days, both methods achieve similar loss levels, indicating that computational gains beyond this threshold yield minimal additional benefits. This suggests MoBA Projection may be preferable for resource-constrained scenarios, while Full Attention Projection becomes competitive at higher scales. The convergence implies that architectural differences between the methods may become less impactful as computational power increases, potentially guiding resource allocation decisions in large-scale model training.