\n
## Scatter Plot: Model Performance Comparison
### Overview
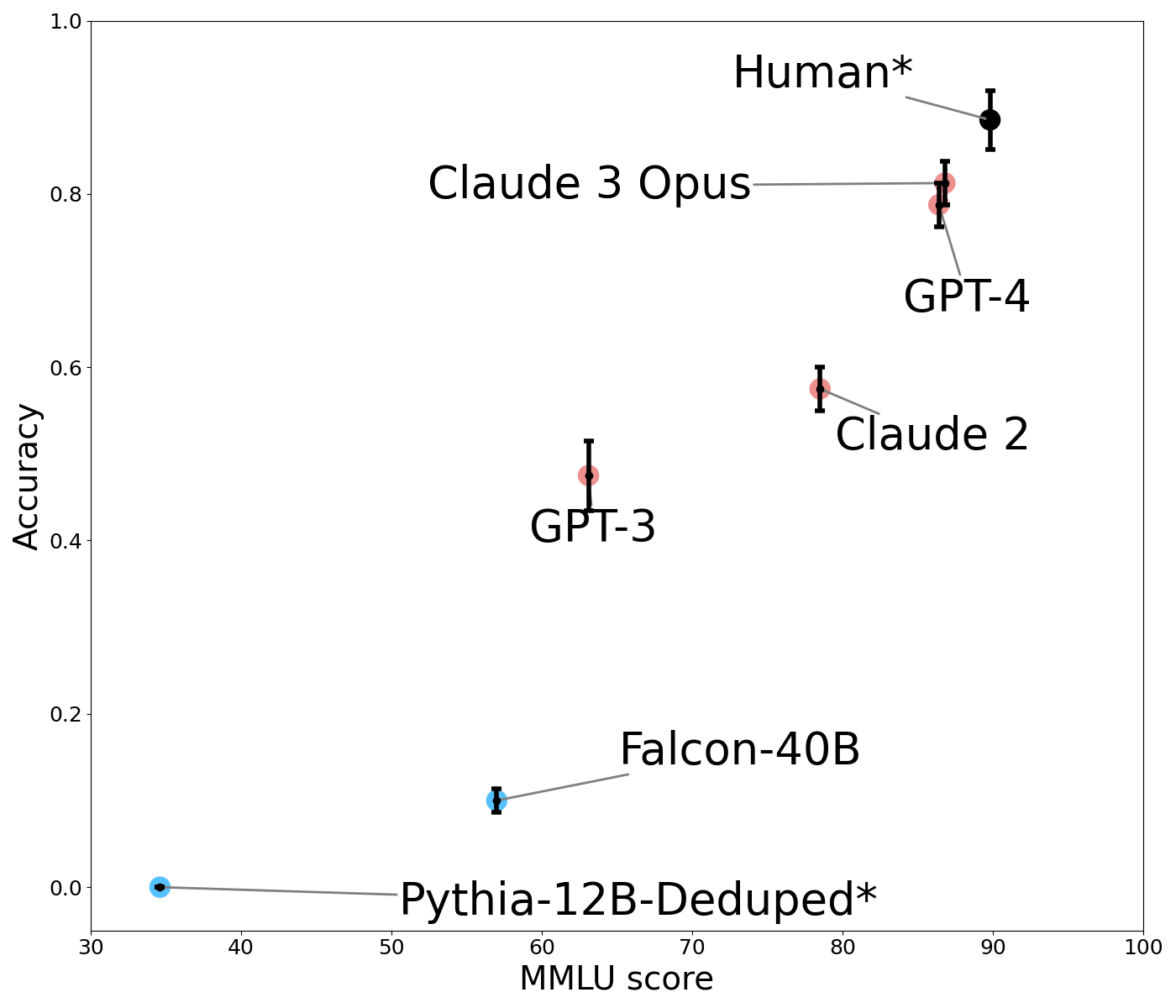
This scatter plot compares the performance of several large language models (LLMs) based on two metrics: MMLU score (Massive Multitask Language Understanding) and Accuracy. Each model is represented by a data point with error bars indicating uncertainty. The plot aims to visualize the trade-off between these two metrics and benchmark model capabilities against human performance.
### Components/Axes
* **X-axis:** MMLU Score, ranging from approximately 30 to 100. Labeled "MMLU score".
* **Y-axis:** Accuracy, ranging from 0.0 to 1.0. Labeled "Accuracy".
* **Data Points:** Represent individual LLMs. Each point has error bars extending horizontally and vertically, indicating the standard deviation or confidence interval.
* **Models:**
* Human\* (Black)
* Claude 3 Opus (Red)
* GPT-4 (Red)
* Claude 2 (Orange)
* GPT-3 (Dark Green)
* Falcon-40B (Blue)
* Pythia-12B-Deduped\* (Blue)
* **Asterisk (\*):** Appears next to "Human" and "Pythia-12B-Deduped", potentially indicating a specific data source or methodology.
### Detailed Analysis
The plot shows a general trend of increasing accuracy with increasing MMLU score. Let's analyze each model's position and error bars:
* **Human\***: Located at approximately (92, 0.95). The error bars are small, indicating high consistency.
* **Claude 3 Opus**: Located at approximately (85, 0.84). Error bars are relatively small.
* **GPT-4**: Located at approximately (85, 0.82). Error bars are relatively small.
* **Claude 2**: Located at approximately (78, 0.62). Error bars are moderate in size.
* **GPT-3**: Located at approximately (62, 0.48). Error bars are moderate in size.
* **Falcon-40B**: Located at approximately (60, 0.12). Error bars are moderate in size.
* **Pythia-12B-Deduped\***: Located at approximately (52, 0.02). Error bars are moderate in size.
The lines connecting the data points to their labels are straight and direct. The color scheme is consistent, with each model having a unique color.
### Key Observations
* **Human performance** sets the upper bound for both MMLU score and Accuracy.
* **Claude 3 Opus** and **GPT-4** are the closest to human performance, exhibiting high scores on both metrics.
* **Claude 2**, **GPT-3**, **Falcon-40B**, and **Pythia-12B-Deduped** show progressively lower performance, with a significant drop in accuracy as MMLU score decreases.
* **Pythia-12B-Deduped** has the lowest accuracy and MMLU score among the models presented.
* The error bars suggest that the performance of some models (e.g., GPT-3, Claude 2) has more variability than others (e.g., Human, Claude 3 Opus).
### Interpretation
The data suggests a strong positive correlation between MMLU score and accuracy for these LLMs. Models with higher MMLU scores generally exhibit higher accuracy. This indicates that the MMLU score is a useful metric for evaluating the overall capabilities of these models.
The proximity of Claude 3 Opus and GPT-4 to human performance suggests that these models are approaching human-level intelligence on the tasks assessed by these metrics. The significant gap between these top-performing models and the others highlights the ongoing advancements in LLM technology.
The asterisk next to "Human" and "Pythia-12B-Deduped" could indicate that the data for these points was obtained using a different methodology or represents a specific subset of human or model performance. Further investigation would be needed to understand the significance of these asterisks.
The error bars provide valuable information about the reliability of the performance measurements. Larger error bars suggest that the model's performance is more sensitive to variations in the input data or evaluation process.