## Pie Charts: Error Distribution in GPT-4o and Claude Opus Models
### Overview
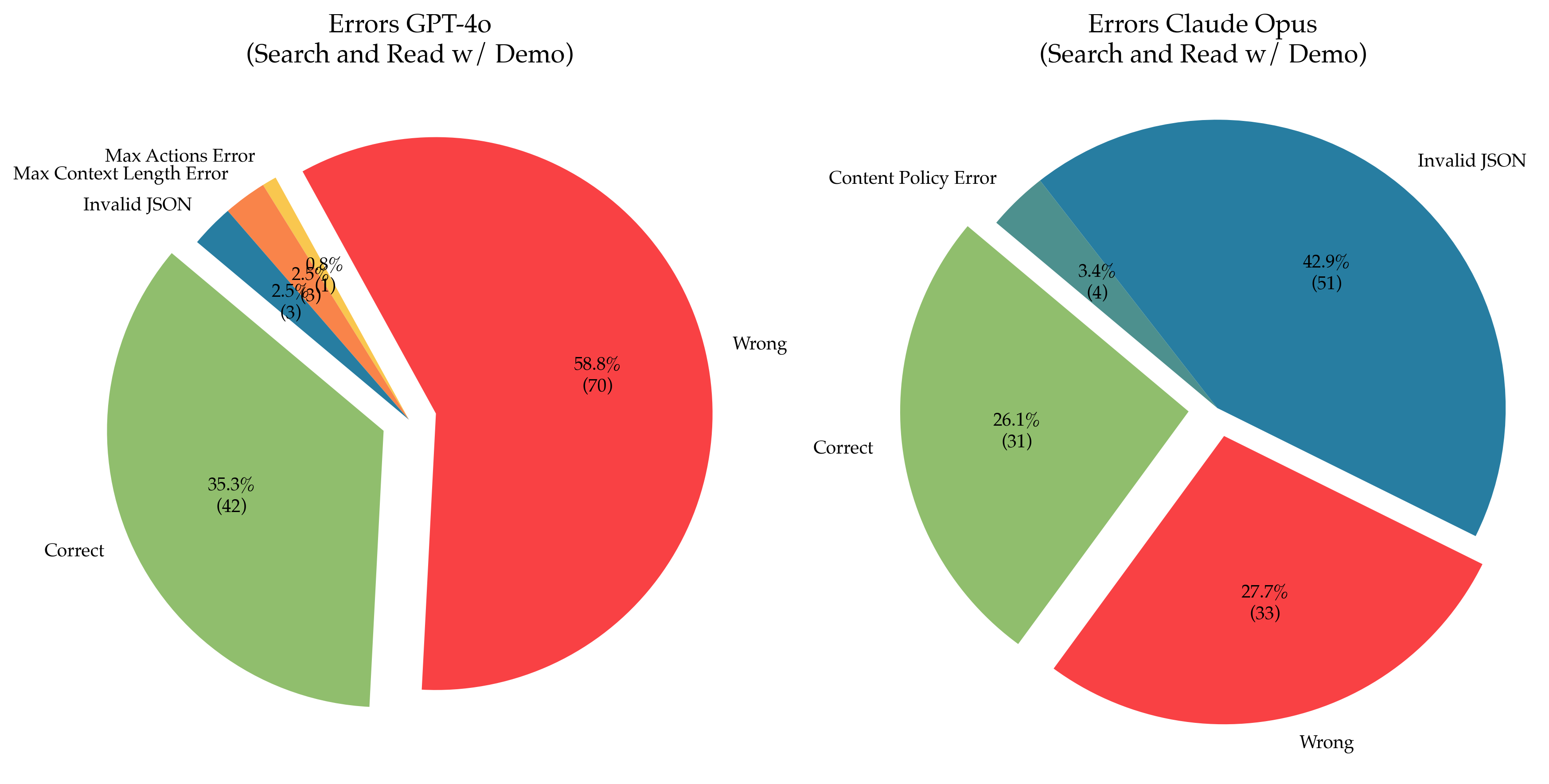
Two pie charts compare error distributions for GPT-4o and Claude Opus models during search and read-with-demo tasks. Each chart categorizes errors into "Correct," "Wrong," and specific error types, with percentages and instance counts labeled.
### Components/Axes
- **X-Axis**: Not applicable (pie charts use radial segments).
- **Y-Axis**: Not applicable.
- **Legend**: Positioned on the right for both charts, with color-coded categories:
- **GPT-4o**:
- Green = Correct (35.3%, 42 instances)
- Red = Wrong (58.8%, 70 instances)
- Blue = Invalid JSON (2.5%, 3 instances)
- Orange = Max Context Length Error (2.5%, 3 instances)
- Yellow = Max Actions Error (0.8%, 1 instance)
- **Claude Opus**:
- Green = Correct (26.1%, 31 instances)
- Red = Wrong (27.7%, 33 instances)
- Blue = Invalid JSON (42.9%, 51 instances)
- Teal = Content Policy Error (3.4%, 4 instances)
### Detailed Analysis
#### GPT-4o Errors
- **Correct**: 35.3% (42 instances), largest green segment.
- **Wrong**: 58.8% (70 instances), dominant red segment.
- **Invalid JSON**: 2.5% (3 instances), small blue segment.
- **Max Context Length Error**: 2.5% (3 instances), small orange segment.
- **Max Actions Error**: 0.8% (1 instance), smallest yellow segment.
#### Claude Opus Errors
- **Correct**: 26.1% (31 instances), smaller green segment than GPT-4o.
- **Wrong**: 27.7% (33 instances), smaller red segment than GPT-4o.
- **Invalid JSON**: 42.9% (51 instances), largest blue segment.
- **Content Policy Error**: 3.4% (4 instances), small teal segment.
### Key Observations
1. **GPT-4o** has a higher "Correct" rate (35.3% vs. 26.1%) but significantly more "Wrong" errors (58.8% vs. 27.7%).
2. **Claude Opus** struggles more with **Invalid JSON** (42.9% vs. 2.5% in GPT-4o) but has fewer "Wrong" answers.
3. GPT-4o has unique error categories (**Max Context Length**, **Max Actions**), while Claude Opus includes **Content Policy Errors**.
4. Both models have minimal overlap in error types, with Claude Opus focusing on input validation and GPT-4o on response accuracy.
### Interpretation
- **GPT-4o** prioritizes response accuracy but may lack robustness in handling input constraints (e.g., context length, action limits). Its high "Wrong" error rate suggests challenges in factual or logical reasoning.
- **Claude Opus** excels in input validation (low "Wrong" errors) but falters in JSON parsing, indicating potential issues with structured data processing. The presence of **Content Policy Errors** implies stricter adherence to ethical guidelines, possibly at the cost of flexibility.
- The **Max Actions Error** in GPT-4o (0.8%) hints at limitations in task execution, while Claude Opus’s absence of this error suggests better action management.
- The disparity in "Correct" rates (35.3% vs. 26.1%) highlights GPT-4o’s superior performance in task completion, despite its higher error diversity.
This analysis underscores trade-offs between accuracy, validation, and constraint handling in large language models.