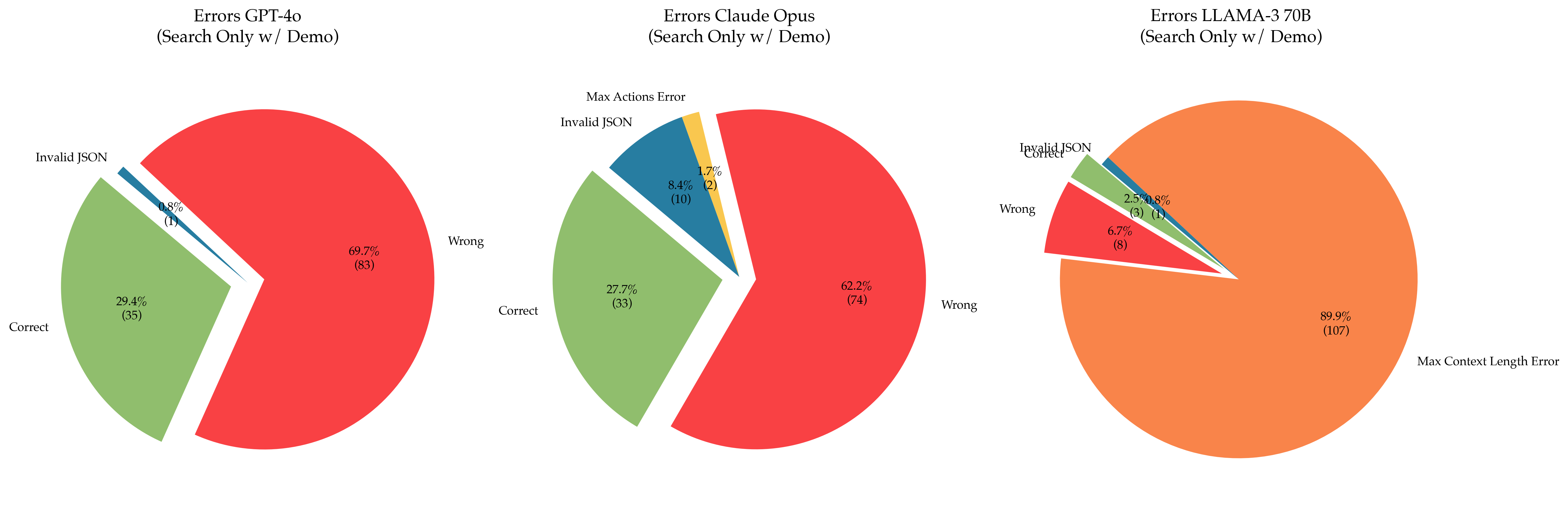
## Pie Charts: Error Distribution Across AI Models (GPT-4o, Claude Opus, LLaMA-3 70B)
### Overview
Three pie charts compare error distributions for three AI models: GPT-4o, Claude Opus, and LLaMA-3 70B. Each chart categorizes errors into "Wrong," "Correct," "Invalid JSON," and model-specific errors ("Max Actions Error" for Claude Opus, "Max Context Length Error" for LLaMA-3 70B). Percentages and raw counts are provided for each category.
---
### Components/Axes
#### Common Elements:
- **Legend**: Positioned on the right side of each chart, mapping colors to error categories.
- **Categories**:
- **Wrong**: Red
- **Correct**: Green
- **Invalid JSON**: Blue (GPT-4o, LLaMA-3 70B) / Yellow (Claude Opus)
- **Model-Specific Errors**:
- **Max Actions Error** (Claude Opus): Yellow
- **Max Context Length Error** (LLaMA-3 70B): Orange
- **Percentages**: Displayed inside each slice, with raw counts in parentheses.
#### Spatial Grounding:
- Legends are consistently placed on the **right** of each chart.
- "Wrong" errors dominate the largest slices in all charts, occupying the **top-left** quadrant visually.
---
### Detailed Analysis
#### 1. **GPT-4o (Search Only w/ Demo)**
- **Wrong**: 69.7% (83 errors) – Dominates the chart in red.
- **Correct**: 29.4% (35 errors) – Green slice, second-largest.
- **Invalid JSON**: 0.8% (1 error) – Tiny blue slice at the bottom.
#### 2. **Claude Opus (Search Only w/ Demo)**
- **Wrong**: 62.2% (74 errors) – Red, largest slice.
- **Correct**: 27.7% (33 errors) – Green, second-largest.
- **Invalid JSON**: 8.4% (10 errors) – Blue slice, smaller than "Correct."
- **Max Actions Error**: 1.7% (2 errors) – Tiny yellow slice.
#### 3. **LLaMA-3 70B (Search Only w/ Demo)**
- **Max Context Length Error**: 89.9% (107 errors) – Orange, overwhelming majority.
- **Wrong**: 6.7% (8 errors) – Red, small slice.
- **Correct**: 2.5% (3 errors) – Green, tiny slice.
- **Invalid JSON**: 0.8% (1 error) – Blue, negligible.
---
### Key Observations
1. **Error Prioritization**:
- GPT-4o and Claude Opus prioritize "Wrong" errors, but GPT-4o has a higher proportion (69.7% vs. 62.2%).
- LLaMA-3 70B is almost entirely dominated by "Max Context Length Error" (89.9%), suggesting a critical limitation in handling long-context tasks.
2. **Invalid JSON**:
- Claude Opus has the highest "Invalid JSON" rate (8.4%), indicating potential issues with input/output formatting or API integration.
3. **Model-Specific Errors**:
- Claude Opus’s "Max Actions Error" (1.7%) and LLaMA-3’s "Max Context Length Error" (89.9%) highlight distinct architectural constraints.
---
### Interpretation
- **GPT-4o** balances "Wrong" and "Correct" errors but struggles with minor JSON validation issues. Its error profile suggests general performance limitations in search tasks.
- **Claude Opus** shows a more balanced error distribution but has a notable "Invalid JSON" rate, possibly due to stricter input validation or integration challenges.
- **LLaMA-3 70B**’s overwhelming "Max Context Length Error" implies it is poorly optimized for tasks requiring extended context, despite its large parameter size. This could reflect training data biases or architectural inefficiencies in context handling.
The data underscores trade-offs between model size, task specificity, and error types. LLaMA-3’s dominance in "Max Context Length Error" suggests it may be unsuitable for applications requiring long-context processing, while GPT-4o and Claude Opus offer more balanced but still error-prone performance.