TECHNICAL ASSET FINGERPRINT
08a0535d873e66be34c2683f
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
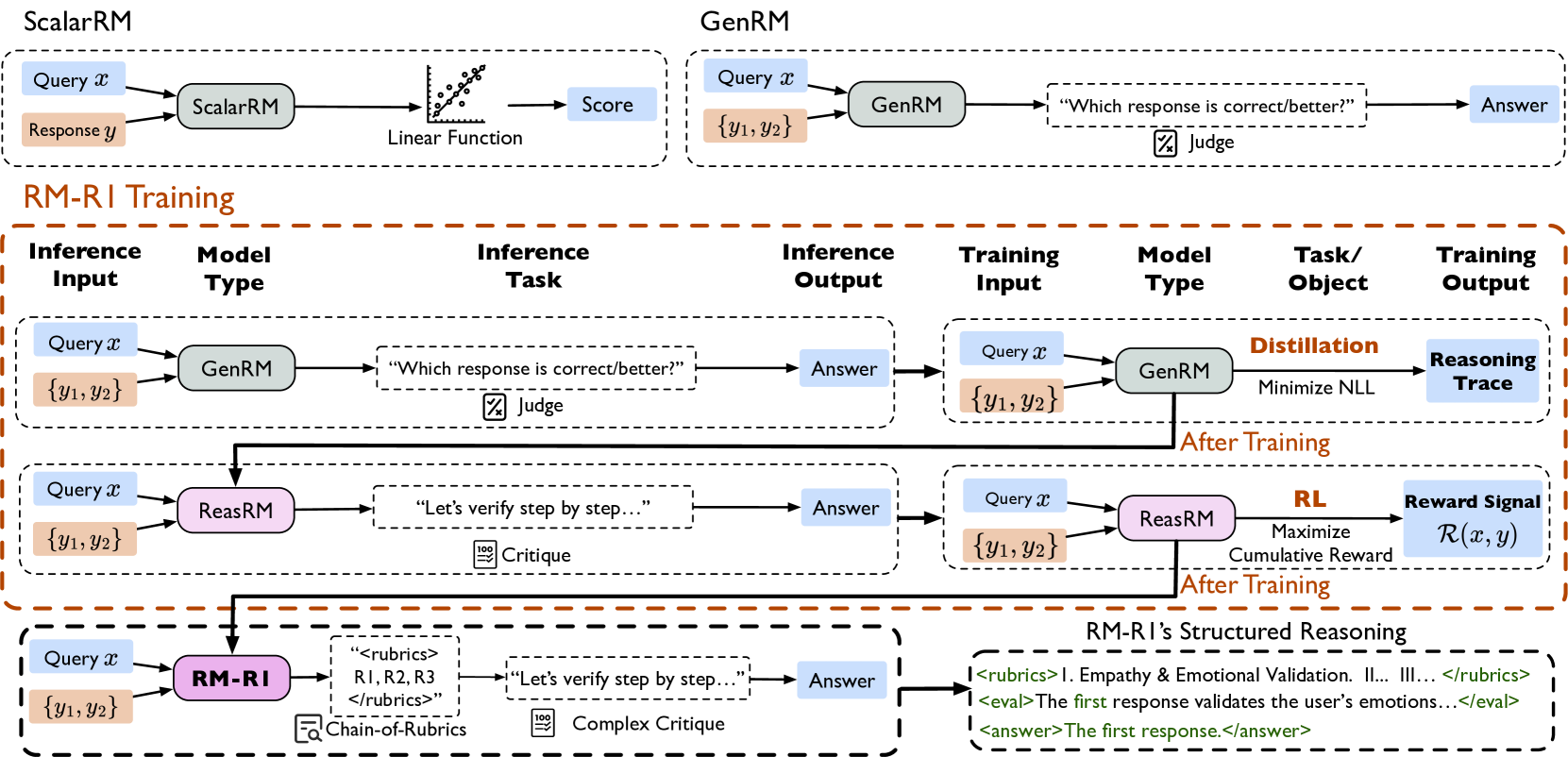
## Diagram: Comparison of Reward Model Architectures and Training Paradigms
### Overview
This image is a technical diagram illustrating and comparing three different approaches to reward modeling (RM) for AI systems: **ScalarRM**, **GenRM**, and a proposed method called **RM-RI**. The diagram is structured to show the inference and training pipelines for each method, highlighting their differences in input, processing, and output. The overall flow demonstrates a progression from simple scalar scoring to generative judgment, and finally to a structured reasoning approach with explicit rubrics.
### Components/Axes
The diagram is divided into three main horizontal sections, each enclosed in a dashed box.
**1. Top Section: ScalarRM vs. GenRM**
* **ScalarRM (Left):**
* **Inference Input:** `Query x` (blue box), `Response y` (orange box).
* **Model Type:** `ScalarRM` (green rounded rectangle).
* **Process:** A `Linear Function` (depicted with a small graph icon).
* **Output:** `Score` (blue box).
* **GenRM (Right):**
* **Inference Input:** `Query x` (blue box), `{y1, y2}` (orange box, indicating multiple responses).
* **Model Type:** `GenRM` (green rounded rectangle).
* **Process:** Asks the question `"Which response is correct/better?"` (dashed box) with a `Judge` icon (document with a checkmark).
* **Output:** `Answer` (blue box).
**2. Middle Section: RM-RI Training**
This section is titled **RM-RI Training** in orange text and is further divided into three rows, each showing an "Inference" phase on the left and a "Training" phase on the right, connected by an arrow labeled **After Training**.
* **Row 1: GenRM-based Training**
* **Inference Phase:** Identical to the standalone GenRM above (Input: `Query x`, `{y1, y2}` -> Model: `GenRM` -> Task: `"Which response is correct/better?"` -> Output: `Answer`).
* **Training Phase:**
* **Training Input:** `Query x`, `{y1, y2}`.
* **Model Type:** `GenRM`.
* **Task/Objective:** `Distillation` with the goal to `Minimize NLL` (Negative Log-Likelihood).
* **Training Output:** `Reasoning Trace` (blue box).
* **Row 2: ReasRM-based Training**
* **Inference Phase:**
* **Inference Input:** `Query x`, `{y1, y2}`.
* **Model Type:** `ReasRM` (pink rounded rectangle).
* **Inference Task:** `"Let's verify step by step..."` (dashed box) with a `Critique` icon (document with a pencil).
* **Inference Output:** `Answer`.
* **Training Phase:**
* **Training Input:** `Query x`, `{y1, y2}`.
* **Model Type:** `ReasRM`.
* **Task/Objective:** `RL` (Reinforcement Learning) with the goal to `Maximize Cumulative Reward`.
* **Training Output:** `Reward Signal` denoted as `R(x, y)` (blue box).
* **Row 3: RM-RI (The Proposed Method)**
* **Inference Phase:**
* **Inference Input:** `Query x`, `{y1, y2}`.
* **Model Type:** `RM-RI` (purple rounded rectangle).
* **Inference Task:** A two-step process:
1. `"<rubrics> R1, R2, R3 </rubrics>"` (dashed box) with a `Chain-of-Rubrics` icon (magnifying glass over a list).
2. `"Let's verify step by step..."` (dashed box) with a `Complex Critique` icon (document with a pencil and a "100" badge).
* **Inference Output:** `Answer`.
* **Training Phase (Implied):** The arrow from the inference output points to a detailed example of the output format.
**3. Bottom Right: RM-RI's Structured Reasoning Output Example**
This box details the expected output format from the RM-RI model:
* `<rubrics> I. Empathy & Emotional Validation. II... III... </rubrics>`
* `<eval>The first response validates the user's emotions...</eval>`
* `<answer>The first response.</answer>`
### Detailed Analysis
The diagram systematically contrasts the three paradigms:
* **ScalarRM:** A traditional, direct regression approach. It maps a query-response pair to a single numerical score via a linear function. The process is opaque and non-explanatory.
* **GenRM:** A generative approach that reframes reward modeling as a multiple-choice question. It takes a query and a set of candidate responses and generates a natural language answer selecting the better one. The training objective is distillation (minimizing NLL) to produce a "Reasoning Trace."
* **ReasRM (Reasoning RM):** A step further, this model generates a step-by-step verification or critique before giving an answer. It is trained via Reinforcement Learning to maximize a cumulative reward signal `R(x, y)`.
* **RM-RI (Reward Modeling with Reasoning and Instruction):** The most complex method. Its inference has two explicit stages:
1. **Chain-of-Rubrics:** First, it generates or references a set of evaluation criteria (`R1, R2, R3`).
2. **Complex Critique:** It then performs a step-by-step verification using those rubrics.
The output is highly structured, containing the rubrics, an evaluation paragraph (`<eval>`), and a final answer (`<answer>`).
### Key Observations
1. **Progression of Complexity:** There is a clear evolution from a single scalar output (ScalarRM) to a simple generative choice (GenRM), to a reasoning trace (ReasRM), and finally to a structured, rubric-guided analysis (RM-RI).
2. **Shift in Training Objectives:** The training goals shift from `Minimize NLL` (GenRM) to `Maximize Cumulative Reward` via RL (ReasRM). RM-RI's training objective is not explicitly stated but is implied to build upon the reasoning and rubric-based structure.
3. **Output Interpretability:** The interpretability of the model's decision increases dramatically. ScalarRM provides only a number. GenRM provides a choice. ReasRM provides a verification trace. RM-RI provides explicit evaluation criteria and a structured justification.
4. **Spatial Layout:** The diagram uses a left-to-right flow for each model's pipeline and a top-to-bottom layout to show the progression of methods. The "After Training" arrows create a clear visual link between the inference and training phases for each model type in the RM-RI Training section.
### Interpretation
This diagram argues for a paradigm shift in reward modeling for AI alignment. It suggests that simple scalar rewards (ScalarRM) are insufficient for capturing nuanced human preferences. While generative models (GenRM) and reasoning models (ReasRM) improve upon this, the proposed **RM-RI** method introduces a crucial layer of **explicit, structured evaluation criteria (rubrics)**.
The core innovation appears to be the "Chain-of-Rubrics" step. By forcing the model to first articulate the evaluation standards (e.g., "Empathy & Emotional Validation"), the subsequent critique and final judgment become more transparent, consistent, and potentially more aligned with complex human values. This structure mimics how a human expert might evaluate responses—against a predefined checklist—making the model's reasoning process auditable and its behavior more reliably steerable. The progression shown implies that future reward models should not just judge *which* response is better, but must be able to explain *why* according to explicit, human-understandable principles.
DECODING INTELLIGENCE...