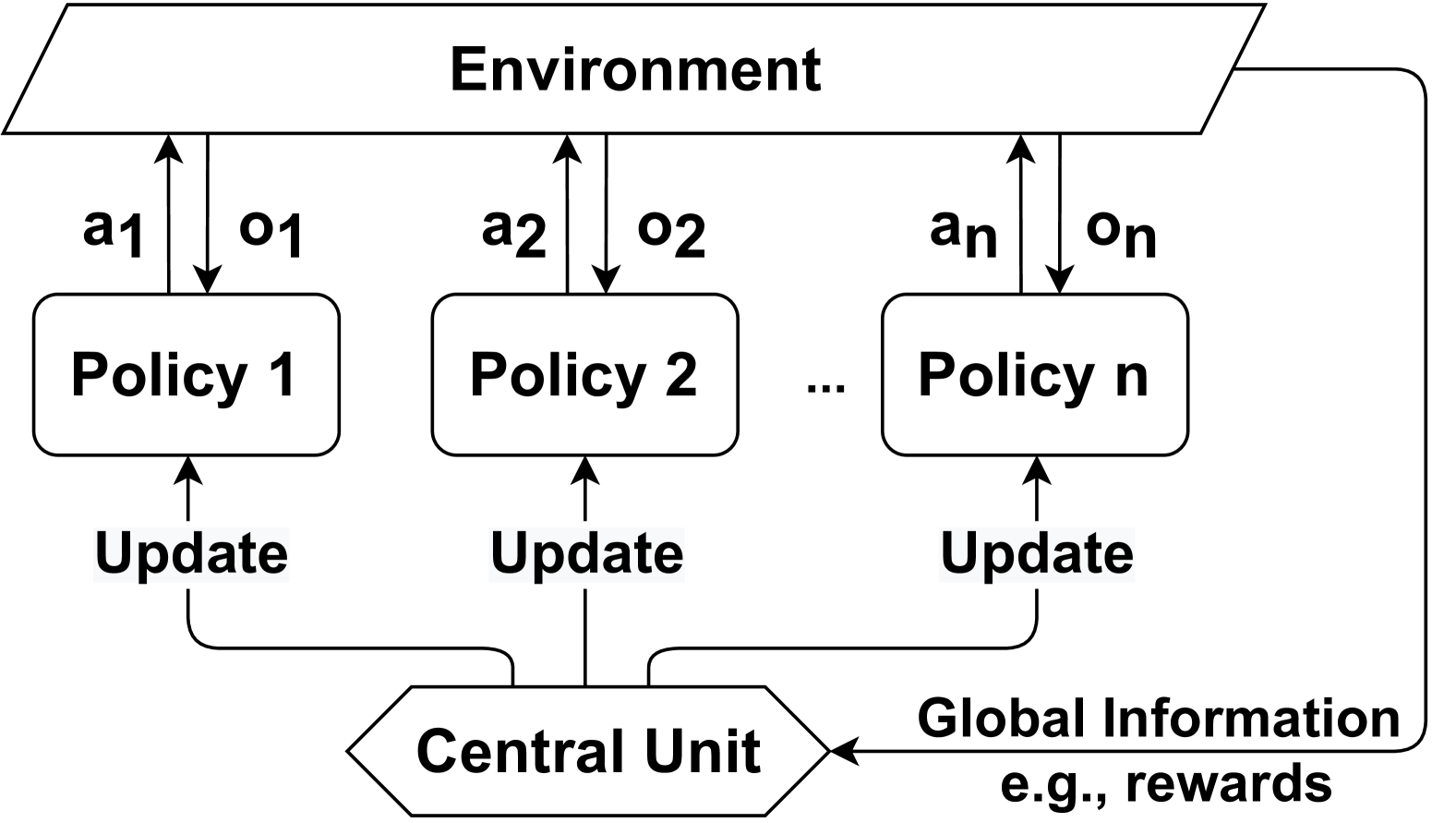
## Diagram: Multi-Agent Reinforcement Learning Architecture
### Overview
The image is a technical block diagram illustrating a multi-agent reinforcement learning (MARL) system architecture. It depicts a centralized training with decentralized execution (CTDE) framework, where multiple independent policies interact with a shared environment and are updated by a central unit using global information.
### Components/Axes
The diagram is composed of three primary horizontal layers and a feedback loop.
**1. Top Layer: Environment**
* A single, wide parallelogram block labeled **"Environment"**.
* This represents the external system or problem space with which the agents interact.
**2. Middle Layer: Policy Agents**
* A series of rounded rectangular blocks representing individual agent policies.
* **Labels:** "Policy 1", "Policy 2", "Policy n". An ellipsis ("...") between "Policy 2" and "Policy n" indicates a variable number of such policies.
* **Interactions with Environment:**
* Each policy block has an upward-pointing arrow labeled with an action: **"a1"**, **"a2"**, **"an"**.
* Each policy block has a downward-pointing arrow labeled with an observation: **"o1"**, **"o2"**, **"on"**.
* This shows each policy `i` sends an action `ai` to the Environment and receives an observation `oi` from it.
**3. Bottom Layer: Central Unit**
* A hexagonal block at the bottom center labeled **"Central Unit"**.
* **Inputs:**
* A long, curved arrow originates from the right side of the "Environment" block, travels down the right edge of the diagram, and points into the right side of the "Central Unit". This arrow is labeled **"Global Information e.g., rewards"**.
* **Outputs:**
* Three arrows originate from the top of the "Central Unit" block.
* Each arrow splits and points upward to a corresponding policy block.
* The label **"Update"** is placed on the vertical segment of each of these three arrows, just before they reach their respective policy blocks ("Policy 1", "Policy 2", "Policy n").
### Detailed Analysis
**Flow and Relationships:**
1. **Decentralized Execution:** Each policy (`Policy 1` through `Policy n`) operates independently during interaction with the environment. They each receive their own local observation (`o1`, `o2`, `on`) and decide on their own action (`a1`, `a2`, `an`).
2. **Centralized Information Gathering:** The "Central Unit" receives "Global Information" from the environment. The example given is "rewards," which could include global state information, joint rewards, or other system-wide metrics not available to individual policies.
3. **Centralized Training/Update:** Using this global information, the "Central Unit" computes and sends an "Update" signal to each individual policy. This update likely contains training gradients, value function estimates, or other parameters to improve the policies' performance. The diagram shows this as a one-way flow from the Central Unit to the policies.
**Spatial Grounding:**
* The **"Environment"** block is positioned at the top, spanning the width of the diagram.
* The **Policy blocks** are arranged horizontally in the middle, evenly spaced.
* The **"Central Unit"** is centered at the bottom.
* The **"Global Information"** label and its associated arrow are located on the right side of the diagram, forming a large feedback loop from the Environment's output back to the Central Unit's input.
* The **"Update"** labels are positioned on the vertical lines connecting the Central Unit to each policy, clearly indicating the direction of the update flow.
### Key Observations
* **Architectural Pattern:** This is a classic representation of the **Centralized Training with Decentralized Execution (CTDE)** paradigm in multi-agent reinforcement learning.
* **Scalability:** The use of "Policy n" and an ellipsis explicitly indicates the architecture is designed to scale to an arbitrary number of agents.
* **Information Asymmetry:** A key design feature is the asymmetry in information. Policies have access only to local observations (`oi`) during execution, while the Central Unit has access to global information for training. This is crucial for learning cooperative behaviors without requiring agents to share all their internal states during deployment.
* **Feedback Loop:** The diagram clearly shows a closed-loop system: Environment -> Policies (Actions) -> Environment -> Global Info -> Central Unit -> Policy Updates -> Policies (improved behavior).
### Interpretation
This diagram illustrates a solution to a fundamental challenge in multi-agent systems: how to train agents to achieve a common goal when they only have a local view of the world. The "Central Unit" acts as a critic or a trainer with a god's-eye view. It uses global success metrics (like total reward) to evaluate the collective performance and then provides targeted feedback ("Update") to each agent to adjust its individual policy.
The architecture suggests a focus on **cooperative tasks**. The policies are not shown competing for resources from the environment; instead, they all feed into a single "Central Unit" that processes "Global Information," implying their actions are coordinated towards a shared objective. The "e.g., rewards" note is critical—it specifies that the global information is not necessarily the full environment state, but could be a distilled signal like the team's cumulative reward, which is more scalable and often sufficient for learning coordination.
In essence, the diagram maps out a learning loop where decentralized actors explore the environment, and a centralized critic uses the outcomes of that exploration to teach them how to act more effectively as a team.