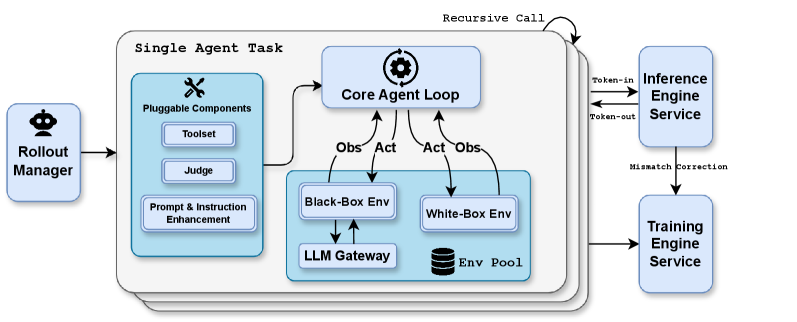
## Diagram: Single Agent Task System Architecture
### Overview
The diagram illustrates a technical system architecture for a single agent task, emphasizing modular components, feedback loops, and interactions between services. It includes a Rollout Manager, Core Agent Loop, Inference Engine Service, Training Engine Service, and environmental components (Black-Box/White-Box Environments, Env Pool). Arrows indicate data flow, recursive calls, and corrections.
### Components/Axes
- **Key Components**:
- **Rollout Manager**: Leftmost block with Reddit mascot icon.
- **Pluggable Components**: Sub-components include Toolset, Judge, and Prompt & Instruction Enhancement.
- **Core Agent Loop**: Central block with gear icon, connected to Observations (Obs) and Actions (Act) via bidirectional arrows.
- **Black-Box Env** and **White-Box Env**: Sub-environments under Core Agent Loop, connected to LLM Gateway and Env Pool.
- **Inference Engine Service**: Rightmost block with "Token-in" and "Token-out" arrows.
- **Training Engine Service**: Connected to Inference Engine Service via "Mismatch Correction" arrow.
- **Env Pool**: Stacked database icon at the bottom, linked to both environments.
- **Flow Arrows**:
- **Recursive Call**: Self-loop on Core Agent Loop.
- **Mismatch Correction**: Connects Inference Engine Service to Training Engine Service.
### Detailed Analysis
- **Rollout Manager**: Initiates the process, feeding into Pluggable Components.
- **Core Agent Loop**: Central decision-making unit with recursive self-processing.
- **Black-Box/White-Box Environments**: Represent different operational modes (opaque vs. transparent).
- **LLM Gateway**: Interface between environments and the agent.
- **Env Pool**: Shared resource pool for environments.
- **Inference/Training Services**: Handle input/output processing and error correction.
### Key Observations
1. **Modular Design**: Components are decoupled (e.g., Pluggable Components, Environments).
2. **Feedback Loops**: Recursive calls and mismatch corrections enable adaptive learning.
3. **Data Flow**: Tokens move from Inference to Training services for refinement.
4. **Environmental Interaction**: Agent interacts with both black-box and white-box environments via the LLM Gateway.
### Interpretation
This architecture suggests a system designed for iterative learning and task execution. The Rollout Manager orchestrates the process, while the Core Agent Loop drives decision-making. The dual environments (Black-Box/White-Box) imply flexibility in handling tasks with varying transparency requirements. The Training Engine Service’s role in correcting mismatches indicates a focus on continuous improvement. The absence of numerical data points emphasizes structural relationships over quantitative metrics, prioritizing system design over performance analytics.