\n
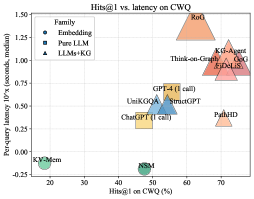
## Scatter Plot: Hits@1 vs. Latency on CWQ
### Overview
This scatter plot visualizes the relationship between Hits@1 (percentage) on the CWQ dataset and per-query latency (in seconds, median) for various models. The models are categorized into three families: Embedding, Pure LLM, and LLMs+KG. Each point represents a model, with its position determined by its performance on the two metrics. The shape of the marker indicates the model family.
### Components/Axes
* **X-axis:** Hits@1 on CWQ (%) - Ranges from approximately 20% to 75%.
* **Y-axis:** Per-query latency 10^x (seconds, median) - Ranges from approximately -0.3 to 1.5. The axis is on a logarithmic scale.
* **Legend:** Located in the top-left corner.
* **Embedding (Blue Circles):** Represents models utilizing embedding techniques.
* **Pure LLM (Blue Squares):** Represents models that are purely Large Language Models.
* **LLMs+KG (Red Triangles):** Represents models combining Large Language Models with Knowledge Graphs.
* **Data Points:** Each point represents a specific model. The points are colored according to their family (as defined in the legend).
### Detailed Analysis
Here's a breakdown of the data points, categorized by family and with approximate values:
**Embedding (Blue Circles):**
* **KV-Mem:** Approximately (22%, -0.25).
* **NSM:** Approximately (42%, -0.3).
**Pure LLM (Blue Squares):**
* **ChatGPT (1 call):** Approximately (47%, 0.35).
* **GPT-4 (1 call):** Approximately (50%, 0.5).
* **UniKQA:** Approximately (48%, 0.45).
* **StructGPT:** Approximately (51%, 0.55).
**LLMs+KG (Red Triangles):**
* **RoQ:** Approximately (62%, 1.3).
* **KG-Agent:** Approximately (68%, 0.9).
* **fiDELIS:** Approximately (69%, 0.8).
* **Think-on-Graph:** Approximately (65%, 1.0).
* **PathHD:** Approximately (72%, 0.3).
**Trends:**
* **Embedding Models:** Generally exhibit low latency and moderate Hits@1 scores.
* **Pure LLM Models:** Show a moderate trade-off between latency and Hits@1.
* **LLMs+KG Models:** Tend to have higher latency but also achieve higher Hits@1 scores. There is a positive correlation between latency and Hits@1 within this family.
### Key Observations
* There's a clear separation between the three model families.
* LLMs+KG models consistently outperform the other two families in terms of Hits@1, but at the cost of increased latency.
* KV-Mem and NSM have the lowest latency, but also the lowest Hits@1 scores.
* PathHD is an outlier within the LLMs+KG family, exhibiting relatively low latency compared to its Hits@1 score.
* RoQ has the highest latency.
### Interpretation
The data suggests a trade-off between accuracy (Hits@1) and speed (latency) in question answering systems. Embedding-based models prioritize speed, while LLMs+KG models prioritize accuracy. Pure LLM models offer a balance between the two. The use of Knowledge Graphs appears to significantly improve accuracy, but introduces computational overhead, resulting in higher latency.
The positioning of PathHD suggests it may be a more efficient LLM+KG model, achieving a relatively high Hits@1 score with lower latency than its counterparts. This could be due to optimizations in its architecture or implementation.
The logarithmic scale on the Y-axis emphasizes the impact of latency, particularly for models with higher latency values. The large difference in latency between models like KV-Mem and RoQ is visually amplified by this scaling.
The scatter plot provides valuable insights for selecting the appropriate model for a given application, depending on the relative importance of accuracy and speed.