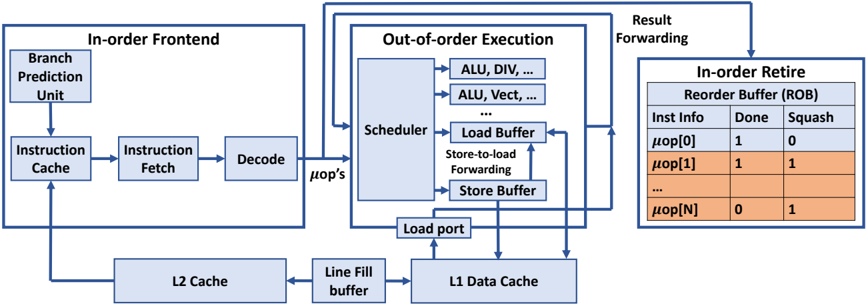
## Diagram: CPU Pipeline Architecture
### Overview
The diagram illustrates a modern CPU pipeline architecture, divided into three primary stages: **In-order Frontend**, **Out-of-order Execution**, and **In-order Retire**. Arrows indicate data flow and control dependencies between components.
### Components/Axes
1. **In-order Frontend**:
- **Branch Prediction Unit**: Predicts branch outcomes.
- **Instruction Cache**: Stores fetched instructions.
- **Instruction Fetch**: Retrieves instructions from memory.
- **Decode**: Translates instructions into micro-operations (µops).
- **L2 Cache**: Secondary cache feeding the frontend.
- **Line Fill Buffer**: Temporarily holds data for cache misses.
2. **Out-of-order Execution**:
- **Scheduler**: Allocates µops to execution units.
- **Execution Units**:
- ALU (Arithmetic Logic Unit)
- DIV (Division Unit)
- Vector Units (e.g., ALU, Vect)
- **Load Buffer**: Stores load instructions awaiting data.
- **Store Buffer**: Holds store instructions for memory writes.
- **Load Port**: Interface for memory load operations.
3. **In-order Retire**:
- **Reorder Buffer (ROB)**: Tracks µops for in-order retirement.
- **Columns**:
- `Inst Info`: Micro-operation identifier.
- `Done`: Completion status (1 = done, 0 = pending).
- `Squash`: Indicates invalidated µops (1 = squashed, 0 = valid).
- **Rows**: Labeled `µop[0]`, `µop[1]`, ..., `µop[N]` for sequential tracking.
### Detailed Analysis
- **Flow**:
1. Instructions are fetched from the **Instruction Cache** and decoded into µops.
2. µops are sent to the **Scheduler**, which dispatches them to execution units (e.g., ALU, DIV).
3. Results are forwarded to the **Load/Store Buffers** for memory operations.
4. Completed µops are tracked in the **ROB**, ensuring in-order retirement despite out-of-order execution.
- **Key Data Points**:
- The **ROB** table shows:
- `µop[0]`: `Done=1`, `Squash=0` (valid and completed).
- `µop[1]`: `Done=1`, `Squash=1` (completed but squashed, likely due to a misprediction).
- `µop[N]`: `Done=0`, `Squash=1` (pending but invalidated).
### Key Observations
- **Out-of-order Execution**: Execution units (ALU, DIV, Vector) operate independently, enabling parallelism.
- **Branch Prediction**: Critical for minimizing pipeline stalls caused by mispredicted branches.
- **ROB Functionality**: Ensures program correctness by retiring µops in program order, even if executed out of order.
- **Squashed µops**: Indicates speculative execution errors (e.g., branch mispredictions).
### Interpretation
This diagram highlights the interplay between **speculative execution** (out-of-order) and **deterministic retirement** (in-order). The **ROB** acts as a synchronization mechanism, resolving dependencies and ensuring that memory operations and results are committed in the correct sequence. The presence of squashed µops (`µop[1]` and `µop[N]`) suggests frequent branch mispredictions or invalidated speculative paths, which could degrade performance. The architecture balances throughput (via out-of-order execution) with correctness (via in-order retirement), a hallmark of modern high-performance CPUs.