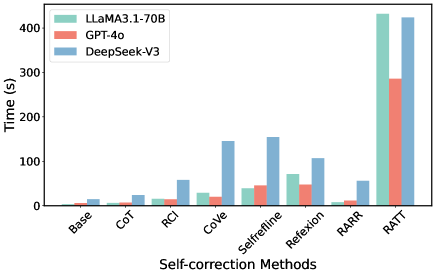
## Bar Chart: Model Performance on Self-Correction Methods
### Overview
The image is a bar chart comparing the performance of three language models (LLaMA3.1-70B, GPT-4o, and DeepSeek-V3) across various self-correction methods. Performance is measured in time (seconds).
### Components/Axes
* **Y-axis:** "Time (s)" with a scale from 0 to 400 in increments of 100.
* **X-axis:** "Self-correction Methods" with the following categories: Base, CoT, RCI, CoVe, Selfrefline, Refexion, RARR, RATT.
* **Legend:** Located at the top-left of the chart.
* LLaMA3.1-70B (light green)
* GPT-4o (light red)
* DeepSeek-V3 (light blue)
### Detailed Analysis
The chart displays the time taken by each model to perform each self-correction method.
* **Base:**
* LLaMA3.1-70B: ~5s
* GPT-4o: ~5s
* DeepSeek-V3: ~8s
* **CoT:**
* LLaMA3.1-70B: ~8s
* GPT-4o: ~8s
* DeepSeek-V3: ~15s
* **RCI:**
* LLaMA3.1-70B: ~15s
* GPT-4o: ~15s
* DeepSeek-V3: ~60s
* **CoVe:**
* LLaMA3.1-70B: ~28s
* GPT-4o: ~20s
* DeepSeek-V3: ~145s
* **Selfrefline:**
* LLaMA3.1-70B: ~70s
* GPT-4o: ~45s
* DeepSeek-V3: ~130s
* **Refexion:**
* LLaMA3.1-70B: ~70s
* GPT-4o: ~50s
* DeepSeek-V3: ~105s
* **RARR:**
* LLaMA3.1-70B: ~10s
* GPT-4o: ~10s
* DeepSeek-V3: ~55s
* **RATT:**
* LLaMA3.1-70B: ~430s
* GPT-4o: ~290s
* DeepSeek-V3: ~430s
### Key Observations
* For most self-correction methods (Base, CoT, RCI, CoVe, Selfrefline, Refexion, RARR), LLaMA3.1-70B and GPT-4o have similar performance, while DeepSeek-V3 generally takes more time.
* The RATT method shows a significant increase in time for all models, with LLaMA3.1-70B and DeepSeek-V3 taking approximately the same amount of time, and GPT-4o taking slightly less.
* DeepSeek-V3 shows the highest time consumption for CoVe, Selfrefline, and Refexion.
### Interpretation
The bar chart illustrates the computational cost (time) associated with different self-correction methods for three language models. The data suggests that the choice of self-correction method can significantly impact the performance of these models. The RATT method, in particular, appears to be computationally expensive for all models. The relative performance of the models varies depending on the specific self-correction method used, indicating that the effectiveness and efficiency of these methods are model-dependent. DeepSeek-V3 generally takes more time than LLaMA3.1-70B and GPT-4o, except for the RATT method where their performance is similar.