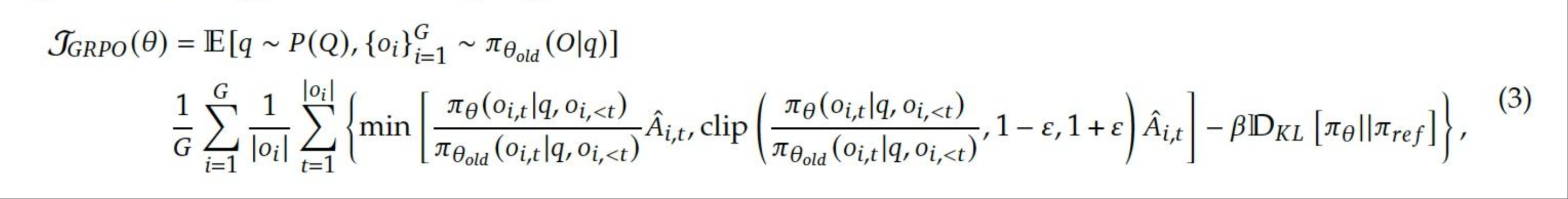## Equation: GRPO Objective Function
### Overview
The image presents a mathematical equation, specifically the objective function for GRPO (likely an algorithm or model). It involves expectation, probabilities, summations, minimum functions, clipping, and a KL divergence term.
### Components/Axes
* **Left-hand side:** $\mathcal{J}_{GRPO}(\theta)$ - This represents the GRPO objective function parameterized by $\theta$.
* **Expectation:** $\mathbb{E}[q \sim P(Q), \{o_i\}_{i=1}^G \sim \pi_{\theta_{old}}(O|q)]$ - The expectation is taken over the distribution $P(Q)$ for variable $q$, and the distribution $\pi_{\theta_{old}}(O|q)$ for the set of variables $\{o_i\}_{i=1}^G$.
* **Summation:** $\frac{1}{G} \sum_{i=1}^G \frac{1}{|o_i|} \sum_{t=1}^{|o_i|}$ - A double summation is performed. The outer sum is over $i$ from 1 to $G$, and the inner sum is over $t$ from 1 to $|o_i|$.
* **Minimum Function:** $\min \left( \frac{\pi_\theta(o_{i,t}|q, o_{i,<t})}{\pi_{\theta_{old}}(o_{i,t}|q, o_{i,<t})} \hat{A}_{i,t}, \text{clip} \left( \frac{\pi_\theta(o_{i,t}|q, o_{i,<t})}{\pi_{\theta_{old}}(o_{i,t}|q, o_{i,<t})}, 1-\epsilon, 1+\epsilon \right) \hat{A}_{i,t} \right)$ - This part calculates the minimum of two terms. The first term involves a ratio of probabilities $\pi_\theta$ and $\pi_{\theta_{old}}$, multiplied by $\hat{A}_{i,t}$. The second term involves clipping the same probability ratio between $1-\epsilon$ and $1+\epsilon$, and then multiplying by $\hat{A}_{i,t}$.
* **KL Divergence:** $-\beta D_{KL}[\pi_\theta || \pi_{ref}]$ - This term subtracts the KL divergence between $\pi_\theta$ and $\pi_{ref}$, scaled by a factor $\beta$.
* **(3)** - Equation number.
### Detailed Analysis or ### Content Details
The equation can be broken down as follows:
1. **$\mathcal{J}_{GRPO}(\theta)$**: The objective function to be optimized.
2. **$\mathbb{E}[q \sim P(Q), \{o_i\}_{i=1}^G \sim \pi_{\theta_{old}}(O|q)]$**: The expectation is taken over trajectories or samples drawn from a distribution $P(Q)$ and a policy $\pi_{\theta_{old}}$.
3. **$\frac{1}{G} \sum_{i=1}^G \frac{1}{|o_i|} \sum_{t=1}^{|o_i|}$**: This is an average over $G$ trajectories, where each trajectory $i$ has length $|o_i|$. The inner sum averages over the time steps $t$ within each trajectory.
4. **$\frac{\pi_\theta(o_{i,t}|q, o_{i,<t})}{\pi_{\theta_{old}}(o_{i,t}|q, o_{i,<t})}$**: This is the probability ratio between the current policy $\pi_\theta$ and the old policy $\pi_{\theta_{old}}$ for a given state-action pair $(o_{i,t}, q)$ at time $t$. $o_{i,<t}$ represents the history of observations up to time $t$.
5. **$\hat{A}_{i,t}$**: This represents the estimated advantage function for the state-action pair $(o_{i,t}, q)$ at time $t$.
6. **$\text{clip} \left( \frac{\pi_\theta(o_{i,t}|q, o_{i,<t})}{\pi_{\theta_{old}}(o_{i,t}|q, o_{i,<t})}, 1-\epsilon, 1+\epsilon \right)$**: This clips the probability ratio to be within the range $[1-\epsilon, 1+\epsilon]$, where $\epsilon$ is a hyperparameter.
7. **$-\beta D_{KL}[\pi_\theta || \pi_{ref}]$**: This is a KL divergence penalty that encourages the policy $\pi_\theta$ to stay close to a reference policy $\pi_{ref}$. $\beta$ is a hyperparameter that controls the strength of the penalty.
### Key Observations
* The objective function aims to maximize the expected return while keeping the policy close to the old policy and a reference policy.
* The clipping function limits the change in the policy, preventing large updates that could destabilize training.
* The KL divergence penalty further regularizes the policy updates.
### Interpretation
The equation represents the objective function for a policy optimization algorithm, likely a variant of Trust Region Policy Optimization (TRPO) or Proximal Policy Optimization (PPO). The goal is to find a policy $\pi_\theta$ that maximizes the expected reward while ensuring that the policy updates are not too large, thus promoting stable learning. The clipping and KL divergence terms serve as regularization techniques to prevent drastic changes in the policy during training. The GRPO objective function balances exploration and exploitation by encouraging the agent to explore new actions while staying close to its previous behavior and a reference policy.