## Pie Charts: Self-Judgement and Self-Difficulty Evaluation for Qwen2.5-14B-Instruct
### Overview
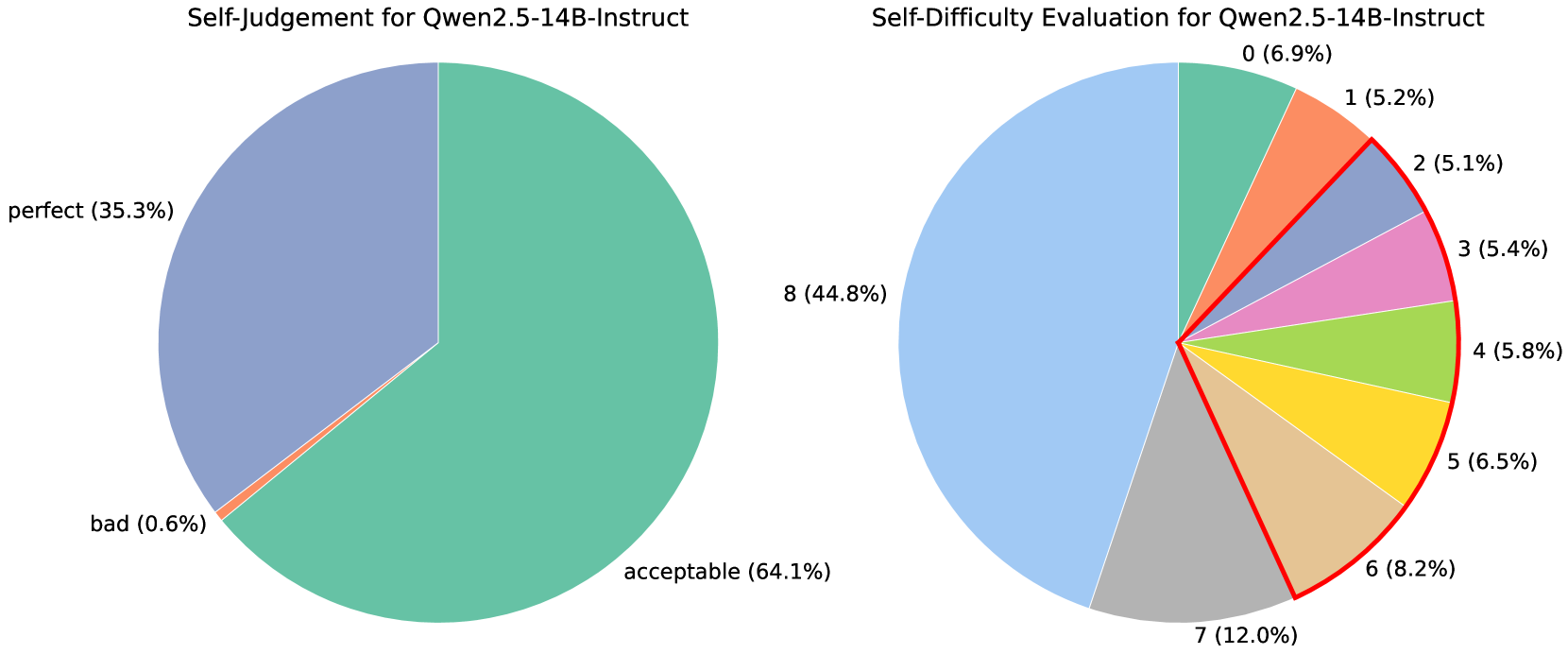
The image contains two pie charts comparing self-assessment metrics for the Qwen2.5-14B-Instruct model. The left chart shows self-judgement results (perfect, acceptable, bad), while the right chart displays self-difficulty evaluations (numerical scale 0–8).
### Components/Axes
#### Left Chart (Self-Judgement):
- **Labels**:
- "perfect (35.3%)" (blue)
- "acceptable (64.1%)" (green)
- "bad (0.6%)" (red)
- **Legend**: Positioned on the left, with color-coded labels.
- **Structure**: Three segments, with "acceptable" dominating the chart.
#### Right Chart (Self-Difficulty Evaluation):
- **Labels**:
- Numerical scale 0–8, each with percentages:
- 8 (44.8%)
- 7 (12.0%)
- 6 (8.2%)
- 5 (6.5%)
- 4 (5.8%)
- 3 (5.4%)
- 2 (5.1%)
- 1 (5.2%)
- 0 (6.9%)
- **Legend**: Positioned on the right, with a gradient color scale (blue for 8, gray for 7, yellow-to-red gradient for 6–0).
- **Structure**: Nine segments, with 8 being the largest slice.
### Detailed Analysis
#### Left Chart:
- **Trends**:
- "acceptable" (64.1%) is the largest segment, followed by "perfect" (35.3%).
- "bad" (0.6%) is negligible.
- **Data Points**:
- Perfect: 35.3%
- Acceptable: 64.1%
- Bad: 0.6%
#### Right Chart:
- **Trends**:
- Difficulty 8 (44.8%) is the most frequent, followed by 7 (12.0%).
- Lower difficulties (0–6) collectively account for 43.1%, with 0 (6.9%) slightly higher than 1–3.
- **Data Points**:
- 8: 44.8%
- 7: 12.0%
- 6: 8.2%
- 5: 6.5%
- 4: 5.8%
- 3: 5.4%
- 2: 5.1%
- 1: 5.2%
- 0: 6.9%
### Key Observations
1. **Self-Judgement**:
- The model rates 64.1% of tasks as "acceptable" and 35.3% as "perfect," indicating high self-confidence.
- Only 0.6% of tasks are rated "bad," suggesting minimal self-criticism.
2. **Self-Difficulty Evaluation**:
- Tasks are predominantly rated as difficulty 8 (44.8%) or 7 (12.0%), implying the model perceives most tasks as highly challenging.
- Lower difficulties (0–6) are less common, with difficulty 0 (6.9%) slightly exceeding difficulties 1–3.
### Interpretation
- **Self-Judgement**: The model’s high "acceptable" and "perfect" ratings suggest it generally performs well on tasks, with minimal self-doubt.
- **Self-Difficulty**: The skew toward higher difficulty ratings (8 and 7) may indicate either:
- The tasks are inherently complex for the model.
- The model overestimates task difficulty, potentially due to calibration issues.
- **Anomalies**:
- The spike in difficulty 0 (6.9%) compared to 1–3 (5.1–5.4%) suggests some tasks were perceived as trivial, possibly due to task design or model bias.
- The dominance of difficulty 8 (44.8%) raises questions about task distribution or model limitations in handling complex scenarios.
The data highlights a discrepancy between self-judgement (high confidence) and self-difficulty (high perceived challenge), which could inform model tuning or task design strategies.