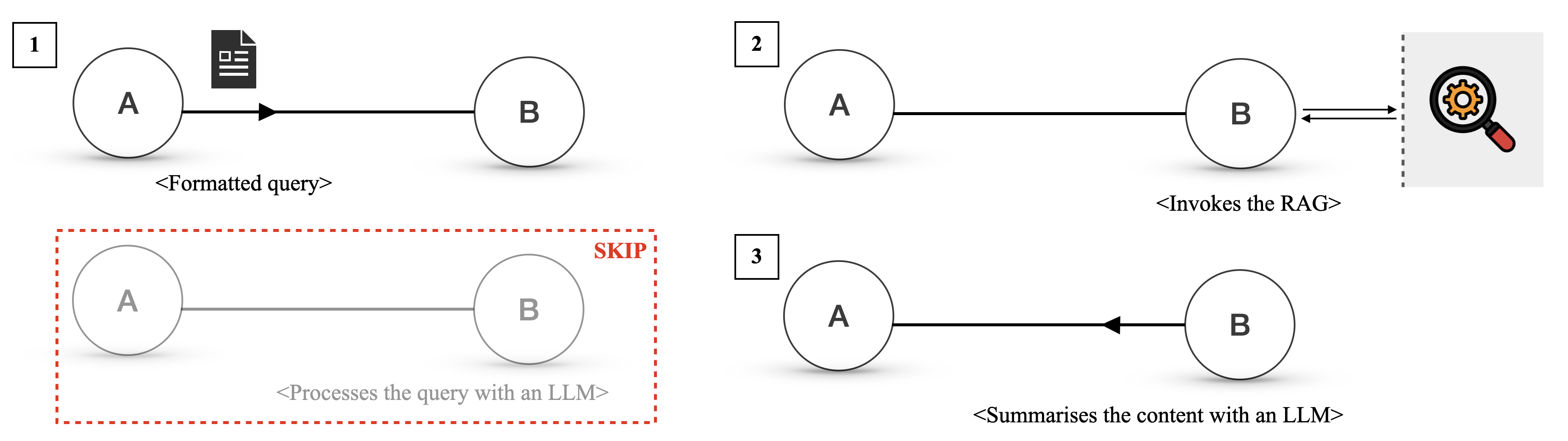
## Flowchart: System Workflow for Query Processing and Content Summarization
### Overview
The diagram illustrates a four-step workflow (labeled 1–3) involving two components, **A** and **B**, with interactions mediated by external systems (RAG and LLM). Arrows indicate directional flow, while dashed boxes highlight alternative pathways. Key annotations include "SKIP" and system-specific labels like "RAG" and "LLM."
---
### Components/Axes
1. **Nodes**:
- **A**: Initiates actions (e.g., formatting queries, invoking systems).
- **B**: Receives inputs and produces outputs (e.g., processing queries, summarizing content).
2. **Arrows**:
- Solid arrows represent direct interactions between A and B.
- Dashed arrows denote indirect or alternative pathways (e.g., RAG, LLM).
3. **Icons**:
- Document icon: Represents a "Formatted query."
- Magnifying glass with gear: Symbolizes the RAG system.
4. **Annotations**:
- "SKIP": Indicates an optional bypass in Step 3.
- Angle-bracket labels (e.g., `<Processes the query with an LLM>`) describe actions.
---
### Detailed Analysis
1. **Step 1**:
- **A** sends a `<Formatted query>` (document icon) to **B** via a solid arrow.
- No intermediate systems involved.
2. **Step 2**:
- **A** invokes the **RAG** system (magnifying glass icon), which then interacts with **B** via a dashed arrow.
- RAG acts as a mediator between A and B.
3. **Step 3**:
- **A** processes the query with an **LLM** (dashed box labeled "SKIP"), bypassing prior steps.
- **B** summarizes content using an LLM (solid arrow).
---
### Key Observations
- **Flow Direction**: All steps follow a left-to-right progression (A → B).
- **Alternative Pathways**:
- Step 3 introduces a "SKIP" option, allowing A to bypass RAG and directly use an LLM.
- RAG (Step 2) and LLM (Step 3) represent distinct processing layers.
- **System Roles**:
- **RAG**: Likely retrieves external data to augment B’s processing.
- **LLM**: Handles both query processing (Step 3) and content summarization (Step 3).
---
### Interpretation
This workflow demonstrates a hybrid system where:
1. **Initial Query Handling**: A formats queries for B (Step 1).
2. **Enhanced Processing**: RAG (Step 2) enriches B’s capabilities by integrating external data.
3. **Optimization**: The "SKIP" option (Step 3) allows direct LLM-based processing, potentially reducing latency or complexity.
4. **Final Output**: B summarizes content using an LLM, suggesting a focus on concise, context-aware outputs.
The diagram emphasizes modularity, with A acting as a controller and B as an executor. The use of RAG and LLM highlights a layered approach to handling queries, balancing precision (via RAG) and efficiency (via LLM shortcuts). The "SKIP" annotation implies adaptability, allowing the system to prioritize speed over exhaustive data retrieval in certain scenarios.