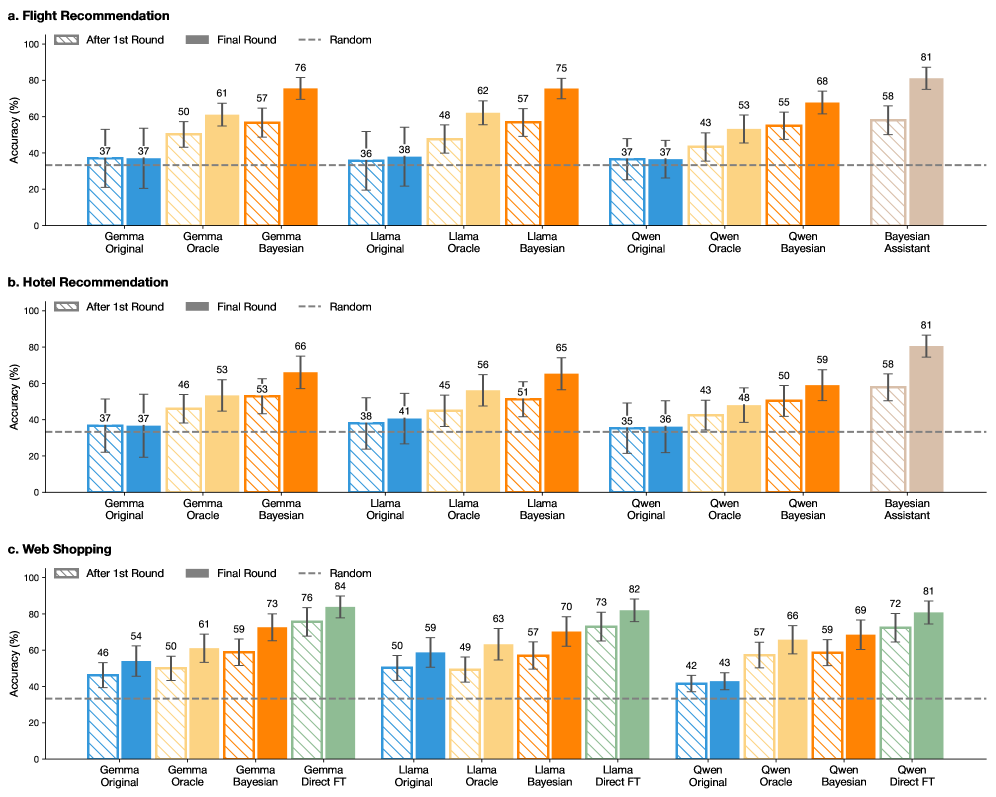
## Grouped Bar Charts: AI Model Accuracy Across Recommendation Tasks
### Overview
The image displays three grouped bar charts comparing the performance of different large language models (LLMs) on three recommendation tasks: Flight, Hotel, and Web Shopping. Each chart measures model accuracy (%) after an initial round and a final round of evaluation, with a baseline "Random" performance indicated. The models compared include variants of Gemma, Llama, and Qwen, alongside a "Bayesian Assistant" or "Direct FT" (Fine-Tuned) variant.
### Components/Axes
* **Chart Layout:** Three vertically stacked sub-charts labeled **a. Flight Recommendation**, **b. Hotel Recommendation**, and **c. Web Shopping**.
* **Y-Axis (All Charts):** Labeled "Accuracy (%)". Scale runs from 0 to 100 in increments of 20.
* **X-Axis (All Charts):** Lists model variants grouped by base model family (Gemma, Llama, Qwen) and training method (Original, Oracle, Bayesian, and Direct FT for Web Shopping only).
* **Legend (Top-Left of each chart):**
* **Pattern:** Diagonally hatched bars represent "After 1st Round". Solid bars represent "Final Round".
* **Color:** Each model family has a distinct color scheme:
* **Gemma:** Blue (Original), Light Orange (Oracle), Dark Orange (Bayesian).
* **Llama:** Blue (Original), Light Orange (Oracle), Dark Orange (Bayesian).
* **Qwen:** Blue (Original), Light Orange (Oracle), Dark Orange (Bayesian).
* **Special Variants:** "Bayesian Assistant" (Brown, in charts a & b) and "Gemma/Llama/Qwen Direct FT" (Green, in chart c).
* **Baseline:** A dashed horizontal line labeled "Random" is present at approximately 33% accuracy across all charts.
### Detailed Analysis
#### **a. Flight Recommendation**
* **Gemma Family:**
* Original: 1st Round ~37%, Final ~37%.
* Oracle: 1st Round ~50%, Final ~61%.
* Bayesian: 1st Round ~57%, Final ~76%.
* **Llama Family:**
* Original: 1st Round ~36%, Final ~38%.
* Oracle: 1st Round ~48%, Final ~62%.
* Bayesian: 1st Round ~57%, Final ~75%.
* **Qwen Family:**
* Original: 1st Round ~37%, Final ~37%.
* Oracle: 1st Round ~43%, Final ~53%.
* Bayesian: 1st Round ~55%, Final ~68%.
* **Bayesian Assistant:** 1st Round ~58%, Final ~81%.
#### **b. Hotel Recommendation**
* **Gemma Family:**
* Original: 1st Round ~37%, Final ~37%.
* Oracle: 1st Round ~46%, Final ~53%.
* Bayesian: 1st Round ~53%, Final ~66%.
* **Llama Family:**
* Original: 1st Round ~38%, Final ~41%.
* Oracle: 1st Round ~45%, Final ~56%.
* Bayesian: 1st Round ~51%, Final ~65%.
* **Qwen Family:**
* Original: 1st Round ~35%, Final ~36%.
* Oracle: 1st Round ~43%, Final ~48%.
* Bayesian: 1st Round ~50%, Final ~59%.
* **Bayesian Assistant:** 1st Round ~58%, Final ~81%.
#### **c. Web Shopping**
* **Gemma Family:**
* Original: 1st Round ~46%, Final ~54%.
* Oracle: 1st Round ~50%, Final ~61%.
* Bayesian: 1st Round ~59%, Final ~73%.
* Direct FT: 1st Round ~76%, Final ~84%.
* **Llama Family:**
* Original: 1st Round ~50%, Final ~59%.
* Oracle: 1st Round ~49%, Final ~63%.
* Bayesian: 1st Round ~57%, Final ~70%.
* Direct FT: 1st Round ~73%, Final ~82%.
* **Qwen Family:**
* Original: 1st Round ~42%, Final ~43%.
* Oracle: 1st Round ~57%, Final ~66%.
* Bayesian: 1st Round ~59%, Final ~69%.
* Direct FT: 1st Round ~72%, Final ~81%.
### Key Observations
1. **Consistent Improvement:** For every model and variant, the "Final Round" accuracy is equal to or higher than the "After 1st Round" accuracy, indicating learning or refinement occurs between rounds.
2. **Bayesian Superiority:** Within each model family (Gemma, Llama, Qwen), the "Bayesian" variant consistently outperforms the "Original" and "Oracle" variants in both rounds across all three tasks.
3. **Top Performer:** The "Bayesian Assistant" (in Flight and Hotel) and the "Direct FT" variants (in Web Shopping) achieve the highest final accuracies, reaching 81-84%.
4. **Task Difficulty:** The "Random" baseline is ~33%. Most "Original" models perform near or slightly above this baseline, especially in Flight and Hotel tasks, suggesting these are challenging tasks without specialized training. Web Shopping shows higher baseline performance for Original models.
5. **Model Family Comparison:** In the Bayesian variants, Gemma and Llama often perform similarly and slightly better than Qwen in Flight and Hotel tasks. In Web Shopping, the Direct FT variants across families show very close performance (81-84%).
### Interpretation
The data demonstrates a clear hierarchy of effectiveness in training methodologies for recommendation tasks. The progression from "Original" (likely base models) to "Oracle" (possibly with some ground-truth guidance) to "Bayesian" (incorporating probabilistic reasoning) shows a significant and consistent gain in accuracy. This suggests that integrating Bayesian or similar probabilistic frameworks substantially improves an LLM's ability to make accurate recommendations.
The exceptional performance of the "Bayesian Assistant" and "Direct FT" models indicates that either a specialized architecture or intensive task-specific fine-tuning is required to achieve state-of-the-art results (80%+ accuracy). The fact that Direct Fine-Tuning is only shown for Web Shopping might imply it was the most amenable to this approach or was the focus of that experiment.
The charts effectively argue that for complex decision-making tasks like recommendations, moving beyond standard instruction-tuning to methods that explicitly handle uncertainty (Bayesian) or involve direct optimization on the task (FT) is crucial for high performance. The consistent pattern across three different domains (flights, hotels, shopping) strengthens the generalizability of this conclusion.