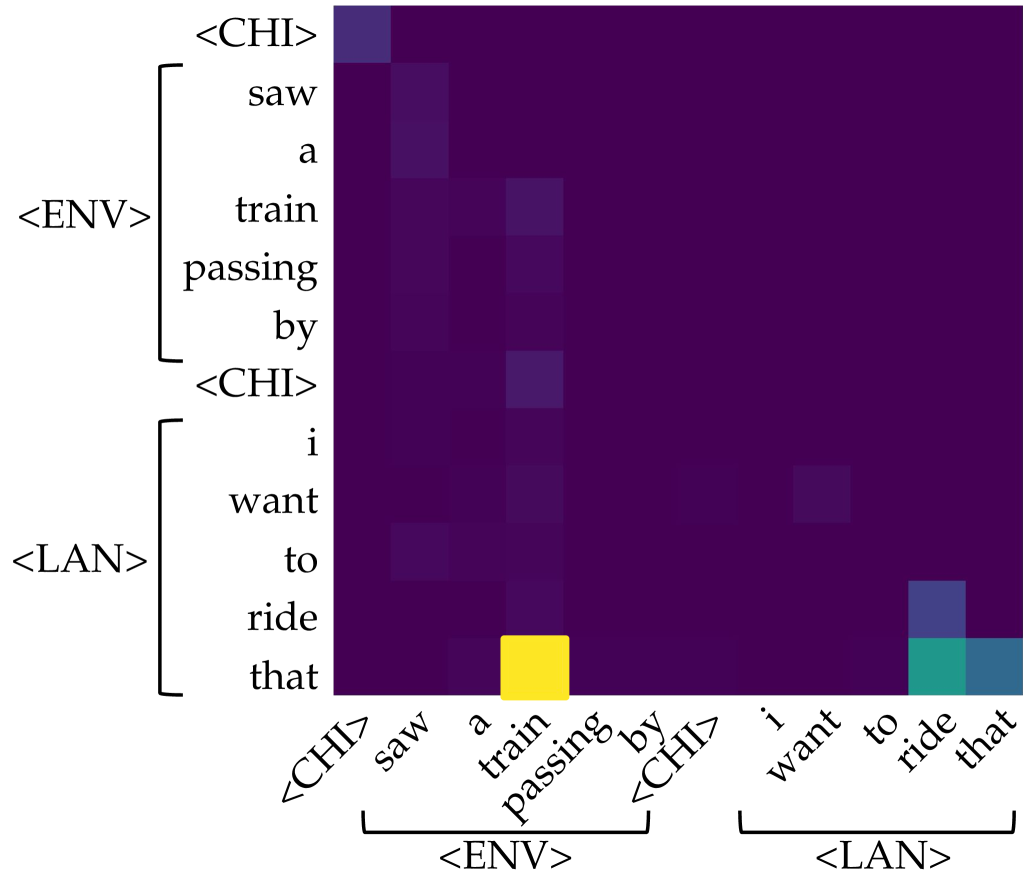
## Heatmap: Attention Matrix
### Overview
The image is a heatmap representing an attention matrix, likely from a machine learning model processing two sentences. The rows represent the words in the input sentences, and the columns represent the words in the output sentences. The color intensity indicates the strength of attention between corresponding words. The sentences are segmented into phrases labeled as `<CHI>`, `<ENV>`, and `<LAN>`.
### Components/Axes
* **Rows (Y-axis):** The rows are labeled with the words of two sentences, grouped into phrases:
* `<CHI>`: (Top)
* `<ENV>`: "saw", "a", "train", "passing", "by"
* `<CHI>`: (Middle)
* `<LAN>`: "i", "want", "to", "ride", "that"
* **Columns (X-axis):** The columns are labeled with the words of the same two sentences, grouped into phrases:
* `<CHI>`: (Left)
* `<ENV>`: "saw", "a", "train", "passing", "by"
* `<CHI>`: (Middle)
* `<LAN>`: "i", "want", "to", "ride", "that"
* **Color Scale:** The heatmap uses a color gradient where darker colors (purple/black) represent lower attention scores and brighter colors (yellow) represent higher attention scores.
### Detailed Analysis
The heatmap shows the attention weights between the words of the input and output sentences. Here's a breakdown of the key areas:
* **`<CHI>` to `<CHI>`:** The attention between the initial `<CHI>` tokens is relatively low, indicated by the dark color.
* **`<ENV>` to `<ENV>`:** There is moderate attention within the `<ENV>` phrase. For example, "saw" attends to "saw", "a" attends to "a", and so on, but the intensity is not very high.
* **`<LAN>` to `<ENV>`:** The word "ride" in `<LAN>` has a strong attention (yellow) to the word "train" in `<ENV>`.
* **`<LAN>` to `<LAN>`:** The word "that" in `<LAN>` has moderate attention (green/blue) to the words "to", "ride", and "that" in `<LAN>`.
* **Other areas:** Most other areas of the heatmap show very low attention, indicated by the dark purple/black color.
### Key Observations
* The model seems to focus attention primarily within the `<ENV>` and `<LAN>` phrases, with a strong connection between "ride" and "train".
* The attention scores are generally low, except for the specific connections mentioned above.
* The `<CHI>` tokens seem to have minimal attention to other words in the sentences.
### Interpretation
The attention matrix visualizes how the model relates different words in the input and output sentences. The strong attention between "ride" and "train" suggests that the model understands the semantic relationship between these words. The attention within the `<ENV>` and `<LAN>` phrases indicates that the model is also capturing the local context of these phrases. The low attention scores in other areas suggest that the model is filtering out irrelevant information.
The heatmap provides insights into the model's decision-making process and can be used to identify potential areas for improvement. For example, if the model is not paying enough attention to certain words, the training data or model architecture could be adjusted to address this issue.