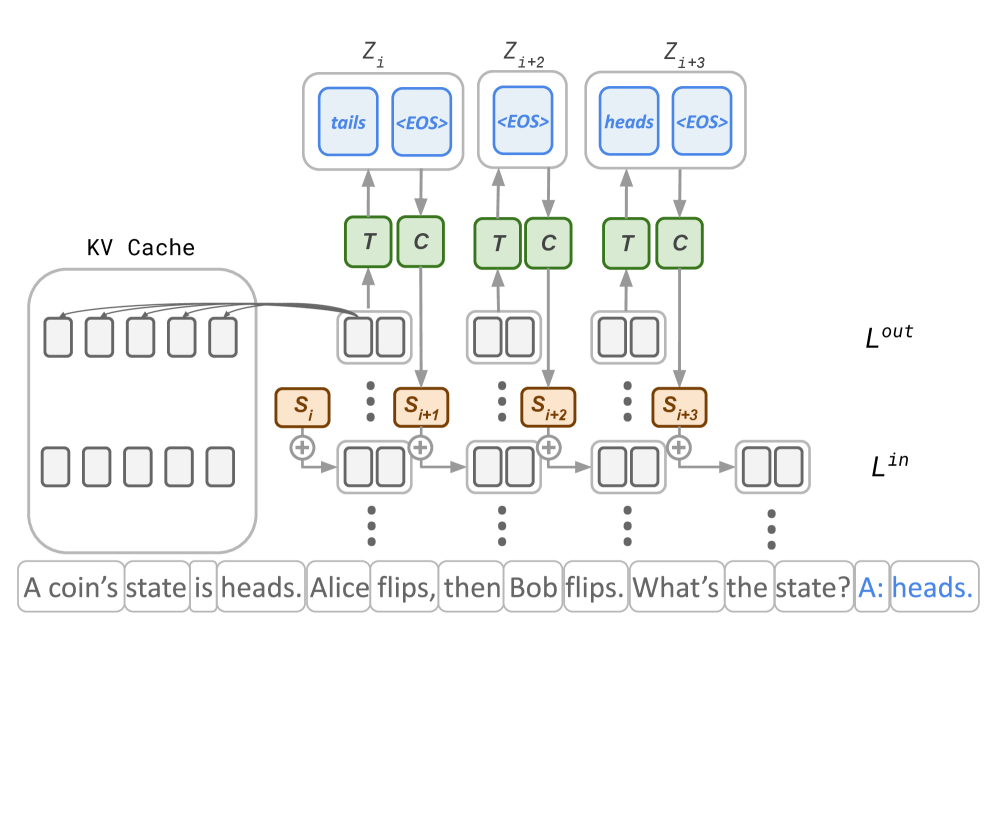
## Diagram: KV Cache and Language Model Layers
### Overview
The image is a diagram illustrating the interaction between a Key-Value (KV) cache and layers of a language model. It shows how the KV cache provides information to the model's layers, influencing the output. The diagram includes input and output layers, intermediate processing steps, and example text input.
### Components/Axes
* **KV Cache:** Located on the left side of the diagram. It contains multiple memory slots, represented as empty rectangles.
* **$L^{in}$:** Denotes the input layer of the language model, positioned at the bottom.
* **$L^{out}$:** Denotes the output layer of the language model, positioned above the input layer.
* **$Z_i$, $Z_{i+2}$, $Z_{i+3}$:** Represent different states or steps in the language model processing. Each state contains tokens.
* $Z_i$ contains "tails" and "<EOS>" tokens.
* $Z_{i+2}$ contains "<EOS>" token.
* $Z_{i+3}$ contains "heads" and "<EOS>" tokens.
* **T, C:** Represent transformations or computations applied to the input. These are located between the $Z$ states and the $L^{out}$ layer.
* **$S_i$, $S_{i+1}$, $S_{i+2}$, $S_{i+3}$:** Represent intermediate states or representations within the language model.
* **"+" symbol:** Indicates an addition or combination operation.
* **Arrows:** Indicate the flow of information between components.
### Detailed Analysis
* **KV Cache Interaction:** The KV Cache on the left has an arrow pointing towards the processing steps of the language model. This indicates that the KV Cache provides information or context to the model. The KV Cache contains 6 rows of 5 empty rectangles.
* **Input Layer ($L^{in}$):** The input layer receives the text "A coin's state is heads. Alice flips, then Bob flips. What's the state? A: heads."
* **Processing Steps:** The input is processed through a series of steps, represented by the rectangles and the addition symbols. The intermediate states $S_i$, $S_{i+1}$, $S_{i+2}$, and $S_{i+3}$ are generated.
* **Transformations (T, C):** The intermediate states are transformed by operations T and C.
* **Output Layer ($L^{out}$):** The transformed states are used to generate the output tokens in $Z_i$, $Z_{i+2}$, and $Z_{i+3}$.
* $Z_i$ outputs "tails" and "<EOS>".
* $Z_{i+2}$ outputs "<EOS>".
* $Z_{i+3}$ outputs "heads" and "<EOS>".
### Key Observations
* The diagram illustrates a language model using a KV Cache to improve its performance.
* The model processes the input text and generates output tokens based on the information in the KV Cache and the transformations applied.
* The "<EOS>" token likely represents the end-of-sequence token.
### Interpretation
The diagram demonstrates how a language model can leverage a KV Cache to store and retrieve information, which is then used to influence the model's output. The KV Cache acts as a memory component, allowing the model to retain information from previous steps and use it to make more informed predictions. The transformations T and C likely represent different types of computations or operations performed on the input. The model processes the input text, updates its internal state, and generates output tokens based on the information in the KV Cache and the applied transformations. The use of "<EOS>" tokens indicates that the model is capable of generating sequences of variable length.