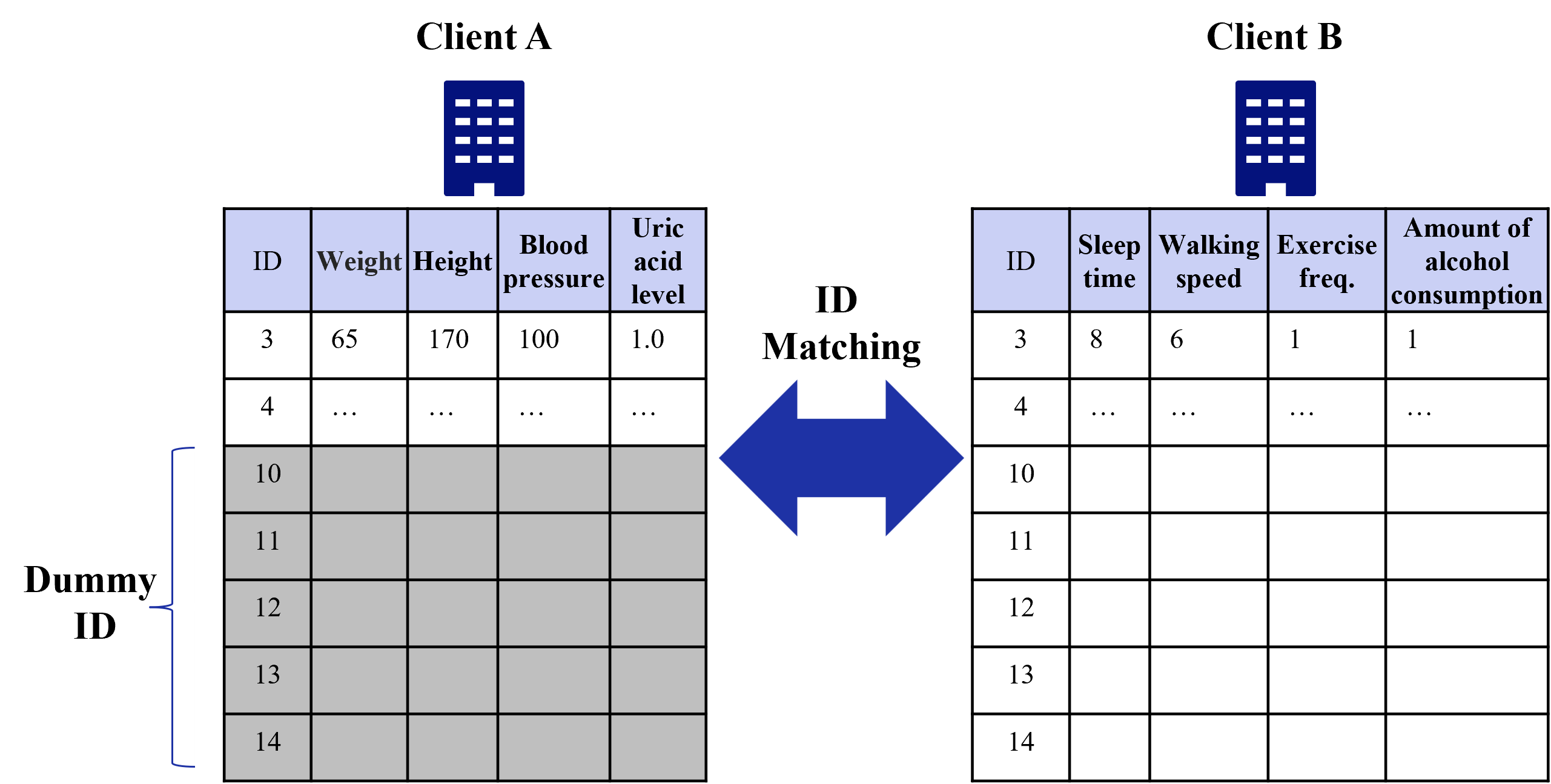
## Diagram: Client Data Matching System
### Overview
The image depicts a two-part data matching system comparing health metrics (Client A) and lifestyle data (Client B), connected by an "ID Matching" arrow. A "Dummy ID" section on the left links to Client B's table, suggesting a data integration or validation process.
### Components/Axes
1. **Client A Table**
- **Columns**: ID, Weight, Height, Blood pressure, Uric acid level
- **Data**:
- ID 3: Weight = 65, Height = 170, Blood pressure = 100, Uric acid level = 1.0
- IDs 4, 10–14: Empty
2. **Client B Table**
- **Columns**: ID, Sleep time, Walking speed, Exercise freq., Amount of alcohol consumption
- **Data**:
- ID 3: Sleep time = 8, Walking speed = 6, Exercise freq. = 1, Alcohol consumption = 1
- IDs 4, 10–14: Empty
3. **Dummy ID Section**
- Labels IDs 10–14 as "Dummy ID" with no associated data.
4. **ID Matching Arrow**
- Connects Dummy ID section to Client B's table, indicating a mapping relationship.
### Detailed Analysis
- **Client A Data**: Only ID 3 contains complete health metrics. Other IDs (4, 10–14) are placeholders.
- **Client B Data**: ID 3 has lifestyle data (e.g., 8 hours sleep, 6 km/h walking speed). Other IDs lack entries.
- **Dummy IDs**: IDs 10–14 are explicitly labeled as "Dummy ID" but have no data in either table.
- **Matching Logic**: The arrow implies Dummy IDs (10–14) are intended to map to Client B's IDs, but no data exists for these in Client B's table.
### Key Observations
1. **Sparse Data**: Only ID 3 has populated entries in both tables, suggesting it may be a test case or primary subject.
2. **Dummy ID Purpose**: The "Dummy ID" label indicates these IDs are placeholders for future data, but they remain unpopulated.
3. **Mismatched Granularity**: Client A focuses on physiological metrics, while Client B tracks behavioral/lifestyle factors, implying separate data collection purposes.
### Interpretation
The diagram illustrates a data integration framework where dummy IDs (10–14) are designed to link Client A's health metrics to Client B's lifestyle data. However, the absence of data for IDs 4, 10–14 in both tables raises questions about the system's current functionality:
- **Testing Hypothesis**: ID 3 may serve as a validation example to demonstrate the matching logic.
- **Data Gaps**: The empty Dummy IDs suggest the system is either in development or awaiting data population.
- **Cross-Client Relationships**: The lack of overlap between Client A and Client B's data categories (health vs. lifestyle) implies the matching process may require additional contextual mapping rules.
The system appears to prioritize structural alignment over actual data integration at this stage, with ID 3 acting as a proof-of-concept anchor.