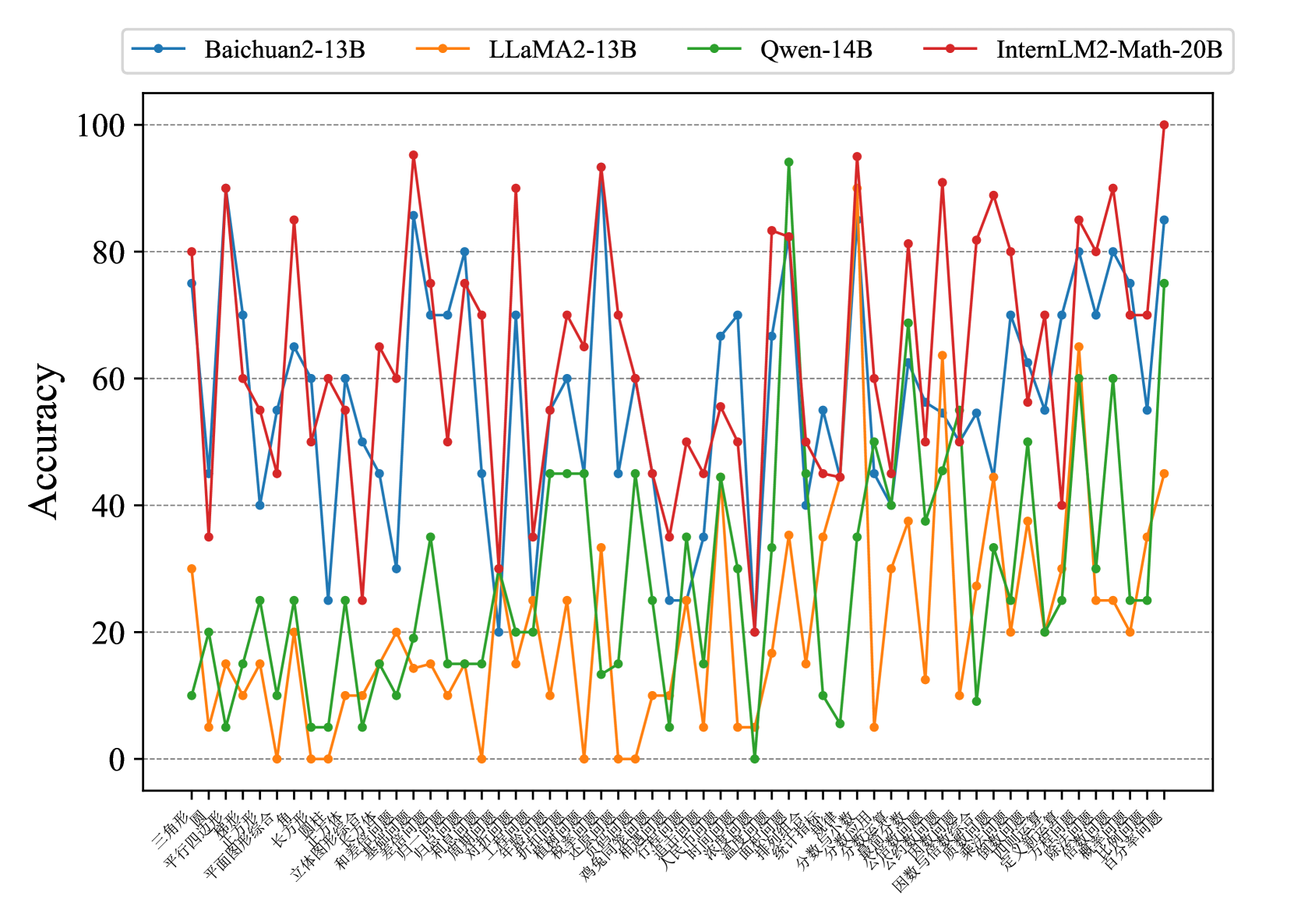
## Line Chart: Model Accuracy Comparison
### Overview
The image is a line chart comparing the accuracy of four different language models (Baichuan2-13B, LLaMA2-13B, Qwen-14B, and InternLM2-Math-20B) across a series of math-related problem types. The y-axis represents accuracy, ranging from 0 to 100. The x-axis represents different problem types, labeled in Chinese.
### Components/Axes
* **Title:** (None visible)
* **X-axis:** Problem Types (labeled in Chinese)
* **Y-axis:** Accuracy (ranging from 0 to 100, with gridlines at intervals of 20)
* **Legend:** Located at the top of the chart.
* Blue: Baichuan2-13B
* Orange: LLaMA2-13B
* Green: Qwen-14B
* Red: InternLM2-Math-20B
### Detailed Analysis
The x-axis labels are in Chinese. Here are the labels and their approximate English translations:
1. 三角形 (sān jiǎo xíng): Triangle
2. 平行四边形 (píng xíng sì biān xíng): Parallelogram
3. 平面图形综合 (píng miàn tú xíng zōng hé): Plane figure synthesis
4. 立体图形 (lì tǐ tú xíng): Solid figure
5. 长方形 (cháng fāng xíng): Rectangle
6. 圆形 (yuán xíng): Circle
7. 和差问题 (hé chā wèn tí): Sum and difference problem
8. 基础问题 (jī chǔ wèn tí): Basic problem
9. 平均问题 (píng jūn wèn tí): Average problem
10. 年龄问题 (nián líng wèn tí): Age problem
11. 归一问题 (guī yī wèn tí): Normalized problem
12. 盈亏问题 (yíng kuī wèn tí): Profit and loss problem
13. 鸡兔同笼 (jī tù tóng lóng): Chicken and rabbit in the same cage (a classic math problem)
14. 对称问题 (duì chèn wèn tí): Symmetry problem
15. 植树问题 (zhí shù wèn tí): Tree planting problem
16. 折扣问题 (zhé kòu wèn tí): Discount problem
17. 税收问题 (shuì shōu wèn tí): Tax problem
18. 工程问题 (gōng chéng wèn tí): Engineering problem
19. 浓度问题 (nóng dù wèn tí): Concentration problem
20. 比例问题 (bǐ lì wèn tí): Proportion problem
21. 利率问题 (lì lǜ wèn tí): Interest rate problem
22. 储蓄问题 (chǔ xù wèn tí): Savings problem
23. 面积问题 (miàn jī wèn tí): Area problem
24. 体积问题 (tǐ jī wèn tí): Volume problem
25. 统计指标 (tǒng jì zhǐ biāo): Statistical indicators
26. 分数/百分数应用 (fēn shù/bǎi fēn shù yìng yòng): Fraction/Percentage application
27. 公倍数/公约数 (gōng bèi shù/gōng yuē shù): Common multiple/Common divisor
28. 因数与倍数 (yīn shù yǔ bèi shù): Factor and multiple
29. 差倍问题 (chā bèi wèn tí): Difference multiple problem
30. 和倍问题 (hé bèi wèn tí): Sum multiple problem
31. 还原问题 (huán yuán wèn tí): Reduction problem
32. 定义新运算 (dìng yì xīn yùn suàn): Define new operation
33. 逻辑推理 (luó jí tuī lǐ): Logical reasoning
34. 包含与排除 (bāo hán yǔ pái chú): Inclusion and exclusion
35. 抽屉原理 (chōu tì yuán lǐ): Pigeonhole principle
36. 日历问题 (rì lì wèn tí): Calendar problem
37. 简单方程 (jiǎn dān fāng chéng): Simple equation
38. 百分率问题 (bǎi fēn lǜ wèn tí): Percentage problem
**Data Series Analysis:**
* **Baichuan2-13B (Blue):** The accuracy fluctuates across problem types, generally ranging between 40 and 80. There are noticeable dips and peaks, indicating varying performance depending on the problem type.
* Triangle: ~75
* Plane figure synthesis: ~45
* Rectangle: ~70
* Statistical indicators: ~55
* Simple equation: ~70
* Percentage problem: ~80
* **LLaMA2-13B (Orange):** This model generally shows lower accuracy compared to the others, often below 40. Its performance is particularly poor on several problem types, with accuracy close to 0.
* Triangle: ~30
* Plane figure synthesis: ~10
* Rectangle: ~0
* Statistical indicators: ~20
* Simple equation: ~25
* Percentage problem: ~45
* **Qwen-14B (Green):** The accuracy of this model varies significantly, with some problem types showing high accuracy (close to 100) and others showing very low accuracy (close to 0).
* Triangle: ~10
* Plane figure synthesis: ~25
* Rectangle: ~15
* Statistical indicators: ~40
* Simple equation: ~45
* Percentage problem: ~70
* **InternLM2-Math-20B (Red):** This model generally exhibits the highest accuracy among the four, often exceeding 60 and reaching close to 100 on some problem types.
* Triangle: ~80
* Plane figure synthesis: ~65
* Rectangle: ~50
* Statistical indicators: ~60
* Simple equation: ~90
* Percentage problem: ~100
### Key Observations
* InternLM2-Math-20B (Red) consistently outperforms the other models across most problem types.
* LLaMA2-13B (Orange) generally has the lowest accuracy.
* Qwen-14B (Green) shows high variance in performance, indicating sensitivity to specific problem types.
* All models exhibit fluctuations in accuracy depending on the problem type, suggesting that certain types of math problems are more challenging for these language models.
### Interpretation
The chart provides a comparative analysis of the accuracy of four language models on a range of math problems. The data suggests that InternLM2-Math-20B is the most proficient at solving these types of problems, while LLaMA2-13B struggles. The varying performance of Qwen-14B highlights the importance of model architecture and training data in determining a model's ability to generalize across different problem types. The fluctuations in accuracy for all models indicate that certain mathematical concepts or problem-solving strategies are more difficult for these models to learn and apply. Further investigation into the specific characteristics of these challenging problem types could inform future model development and training strategies.