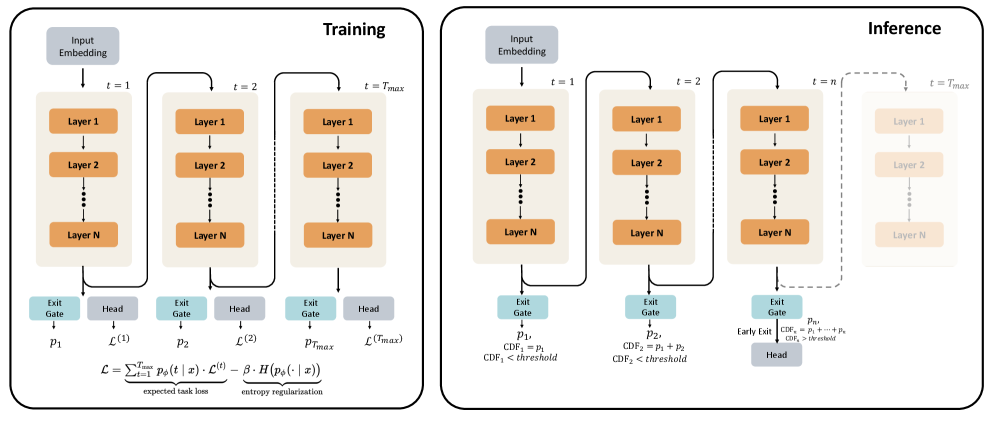
## Diagram: Neural Network Training and Inference Architecture
### Overview
The diagram illustrates a neural network architecture with explicit training and inference phases. It emphasizes dynamic computation through exit gates and confidence thresholds, enabling early termination of processing during inference. The architecture includes multiple layers, task-specific heads, and a confidence-driven early exit mechanism.
### Components/Axes
1. **Training Phase (Left Side)**
- **Input Embedding**: Initial data representation
- **Layers (1 to N)**: Stacked processing units
- **Exit Gates**: Decision points at each time step (t=1, t=2, ..., t=T_max)
- **Heads**: Task-specific output modules (L(1), L(2), ..., L(T_max))
- **Loss Function**:
```
L = Σ_{t=1}^{T_max} [p_φ(t|x) · L(t)] - β · H(p_φ(·|x))
```
- First term: Expected task loss
- Second term: Entropy regularization
2. **Inference Phase (Right Side)**
- **Input Embedding**: Same as training
- **Layers (1 to N)**: Identical to training architecture
- **Exit Gates**: Confidence-driven termination points
- **Heads**: Task-specific outputs with cumulative confidence thresholds
- **Confidence Thresholds**:
- CDF₁ = p₁ (t=1)
- CDF₂ = p₁ + p₂ (t=2)
- CDFₙ = p₁ + ... + pₙ (t=n)
### Detailed Analysis
1. **Training Flow**
- Input embedding → Sequential processing through N layers
- At each time step t:
- Exit gate computes probability p_t
- Head L(t) generates task-specific output
- Loss accumulates weighted task losses with entropy regularization
2. **Inference Flow**
- Input embedding → Sequential processing through N layers
- At each time step t:
- Exit gate computes cumulative confidence CDF_t
- If CDF_t < threshold: Continue processing
- If CDF_t ≥ threshold: Early exit with head output
3. **Key Equations**
- Loss function balances task performance (first term) and model uncertainty (second term)
- Confidence thresholds enable adaptive computation during inference
### Key Observations
1. **Dynamic Computation**
- Training phase shows fixed computation path (all layers processed)
- Inference phase introduces early exit capability based on confidence
2. **Confidence Thresholding**
- Cumulative distribution functions (CDFs) determine exit points
- Thresholds increase with processing depth (CDF₁ < CDF₂ < ... < CDFₙ)
3. **Architectural Symmetry**
- Training and inference share identical layer structure
- Exit gates and heads are consistent across both phases
4. **Temporal Progression**
- Time steps (t=1 to t=T_max) represent sequential processing
- Dashed lines in inference indicate optional early termination
### Interpretation
This architecture demonstrates a **confidence-aware neural network** that optimizes computation efficiency without sacrificing accuracy. The training phase learns to balance task performance with model uncertainty through entropy regularization. During inference, the model dynamically terminates processing when confidence thresholds are met, reducing computational cost for easier samples while maintaining accuracy for complex cases.
The early exit mechanism introduces a **computation-accuracy tradeoff** controlled by threshold values. Lower thresholds enable more aggressive early exits (faster but potentially less accurate), while higher thresholds preserve more computation (more accurate but slower). This design is particularly valuable for resource-constrained environments or real-time applications where processing speed is critical.
The entropy regularization term in the loss function prevents overconfidence by encouraging the model to maintain uncertainty awareness, which directly informs the confidence thresholds used during inference. This creates a closed-loop system where training objectives directly enable efficient inference behavior.