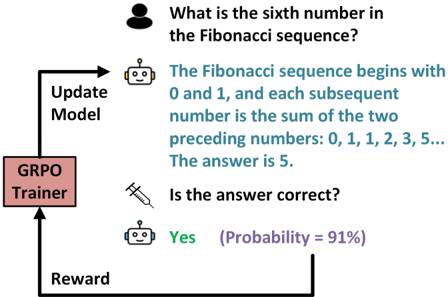
## Diagram: GRPO Trainer Feedback Loop
### Overview
The image depicts a diagram illustrating a feedback loop involving a GRPO (presumably an AI model) answering a question about the Fibonacci sequence. The diagram shows the interaction between a user, the AI model, and a reward mechanism that updates the model based on the correctness of the answer.
### Components/Axes
* **User Question:** "What is the sixth number in the Fibonacci sequence?" (represented by a human icon)
* **AI Model Response:** "The Fibonacci sequence begins with 0 and 1, and each subsequent number is the sum of the two preceding numbers: 0, 1, 1, 2, 3, 5... The answer is 5." (represented by a robot icon)
* **Correctness Check:** "Is the answer correct?" (represented by a syringe icon)
* **AI Model Confirmation:** "Yes (Probability = 91%)" (represented by a robot icon)
* **GRPO Trainer:** A rectangular block labeled "GRPO Trainer"
* **Update Model:** Text label with an arrow pointing from the GRPO Trainer to the AI Model Response.
* **Reward:** Text label with an arrow pointing from the AI Model Confirmation to the GRPO Trainer.
### Detailed Analysis
The diagram illustrates the following flow:
1. A user poses a question about the Fibonacci sequence.
2. The AI model provides an answer, including the sequence and the sixth number.
3. A correctness check is performed.
4. The AI model confirms the answer with a probability of 91%.
5. The GRPO Trainer receives a reward based on the correctness of the answer.
6. The GRPO Trainer updates the AI model based on the reward.
### Key Observations
* The diagram highlights the interaction between a user, an AI model, and a reward mechanism.
* The AI model's response includes both the Fibonacci sequence and the answer to the question.
* The AI model expresses confidence in its answer with a probability of 91%.
* The GRPO Trainer plays a crucial role in updating the AI model based on the reward.
### Interpretation
The diagram demonstrates a reinforcement learning process where the AI model learns to answer questions about the Fibonacci sequence through a feedback loop. The GRPO Trainer uses the reward signal to update the model, improving its accuracy and confidence over time. The 91% probability suggests that the model is relatively confident in its answer, indicating that it has learned the Fibonacci sequence well. The diagram illustrates a simplified example of how AI models can be trained to solve problems through reinforcement learning.