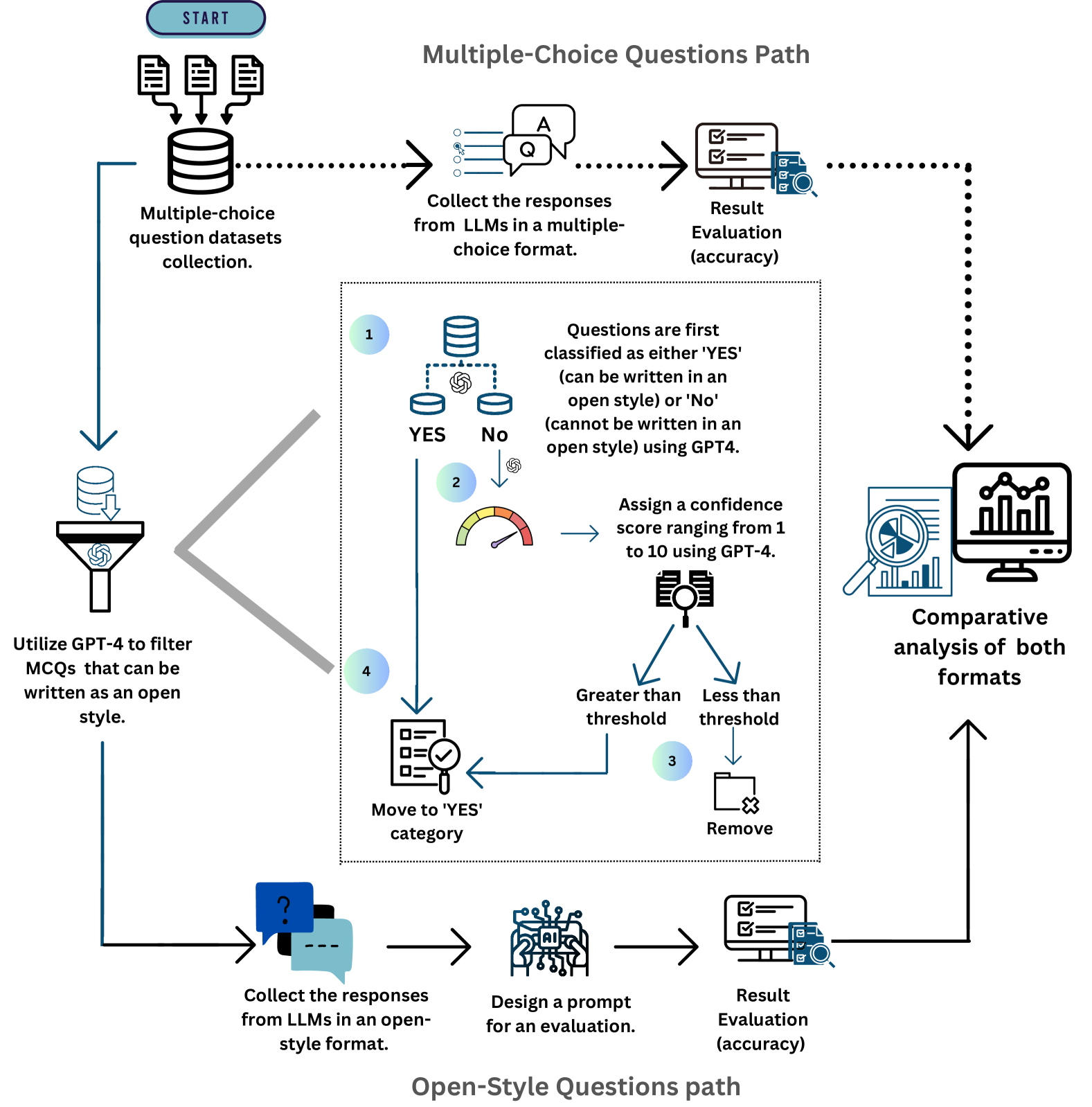
## Diagram: LLM Evaluation Workflow for Multiple-Choice and Open-Style Questions
### Overview
The image is a technical flowchart diagram illustrating a two-path workflow for evaluating Large Language Model (LLM) performance. The process begins with a collection of multiple-choice question (MCQ) datasets and diverges into separate evaluation pipelines for "Multiple-Choice Questions Path" (top) and "Open-Style Questions Path" (bottom). A central, detailed sub-process filters and classifies the MCQs to determine which can be converted into an open-ended format. The workflow culminates in a comparative analysis of the results from both evaluation formats.
### Components/Axes
The diagram is structured as a flowchart with the following key components:
- **Start Node:** A blue rounded rectangle labeled "START" at the top-left.
- **Data Source:** An icon of a database labeled "Multiple-choice question datasets collection."
- **Two Main Paths:**
1. **Multiple-Choice Questions Path:** A horizontal flow across the top of the diagram.
2. **Open-Style Questions Path:** A horizontal flow across the bottom of the diagram.
- **Central Processing Block:** A large, dashed-border rectangle in the center containing a detailed 4-step filtering and classification sub-process.
- **Icons:** Various icons represent actions (funnel, magnifying glass, gauge, checklist), data (databases, documents), and analysis (computer with charts).
- **Arrows:** Solid and dotted arrows indicate the flow of data and process steps. A large, grey, double-headed arrow connects the initial data source to the central processing block.
- **Final Output:** A computer monitor icon labeled "Comparative analysis of both formats" on the right side, which receives input from both main paths.
### Detailed Analysis
The workflow proceeds as follows:
**1. Initial Data Flow:**
- The process starts at the "START" node.
- Data flows to the "Multiple-choice question datasets collection" (database icon).
- From here, the data splits:
- **Path A (Top):** Flows directly into the "Multiple-Choice Questions Path."
- **Path B (Left & Center):** Flows into a funnel icon labeled "Utilize GPT-4 to filter MCQs that can be written as an open style." This filtered data then enters the central processing block.
**2. Multiple-Choice Questions Path (Top Flow):**
- **Step 1:** "Collect the responses from LLMs in a multiple-choice format." (Icon: Speech bubbles with 'Q' and 'A').
- **Step 2:** "Result Evaluation (accuracy)." (Icon: Computer monitor with a checklist and magnifying glass).
- The output of this evaluation flows via a dotted arrow to the final "Comparative analysis" stage.
**3. Central Processing Block (Filtering & Classification):**
This block details how MCQs are prepared for the open-style path. It contains four numbered steps:
- **Step 1:** "Questions are first classified as either 'YES' (can be written in an open style) or 'No' (cannot be written in an open style) using GPT4." This is depicted with a database icon splitting into "YES" and "No" paths.
- **Step 2:** For the "No" path, the system will "Assign a confidence score ranging from 1 to 10 using GPT-4." (Icon: A gauge/meter).
- **Step 3:** A decision point based on the confidence score. If the score is "Greater than threshold," the question is moved to the "YES" category. If "Less than threshold," it is "Remove[d]." (Icon: A folder with an 'X').
- **Step 4:** The final action for approved questions is "Move to 'YES' category." (Icon: A checklist with a magnifying glass).
**4. Open-Style Questions Path (Bottom Flow):**
- **Step 1:** "Collect the responses from LLMs in an open-style format." (Icon: Speech bubbles with a question mark and ellipsis).
- **Step 2:** "Design a prompt for an evaluation." (Icon: A brain/chip circuit icon labeled "AI").
- **Step 3:** "Result Evaluation (accuracy)." (Icon: Same as in the MCQ path).
- The output of this evaluation flows via a solid arrow to the final "Comparative analysis" stage.
**5. Final Stage:**
- Both the MCQ path (dotted arrow) and the Open-Style path (solid arrow) feed into the "Comparative analysis of both formats" (icon: computer monitor with bar and pie charts).
### Key Observations
- **Parallel Structure:** The diagram clearly shows two parallel evaluation pipelines (MCQ vs. Open-Style) originating from the same source data.
- **Central Filtering Mechanism:** A significant portion of the diagram is dedicated to the nuanced process of determining which MCQs are suitable for conversion to an open-ended format, using GPT-4 for both classification and confidence scoring.
- **Role of GPT-4:** GPT-4 is explicitly mentioned as a tool for two key tasks: initial filtering of MCQs and assigning confidence scores during classification.
- **Evaluation Consistency:** The "Result Evaluation (accuracy)" step uses identical icons and labels in both paths, suggesting a consistent evaluation metric is applied to both response formats.
- **Flow Direction:** The overall flow is from left (data source) to right (comparative analysis), with the central block acting as a processing hub for the bottom path.
### Interpretation
This diagram outlines a methodology for rigorously comparing LLM performance across two fundamental question formats. The core insight is that not all multiple-choice questions can or should be converted into open-ended questions. The central filtering process is critical for ensuring a valid comparison; it uses an LLM (GPT-4) to create a high-quality, "open-style" test set derived from MCQs.
The workflow suggests that the ultimate goal is not just to evaluate accuracy in isolation, but to perform a **comparative analysis**. This implies the researchers are interested in understanding the *delta* in LLM performance when the same underlying knowledge is tested via constrained selection (MCQ) versus free-form generation (Open-Style). Such an analysis could reveal biases in MCQ design, strengths/weaknesses of different LLMs in recall vs. reasoning, or the impact of question format on measured accuracy. The use of a confidence threshold in the filtering step adds a layer of quality control, ensuring that only questions reliably convertible to an open format are included in the comparative study.