TECHNICAL ASSET FINGERPRINT
1508f02fb9659efba1787157
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
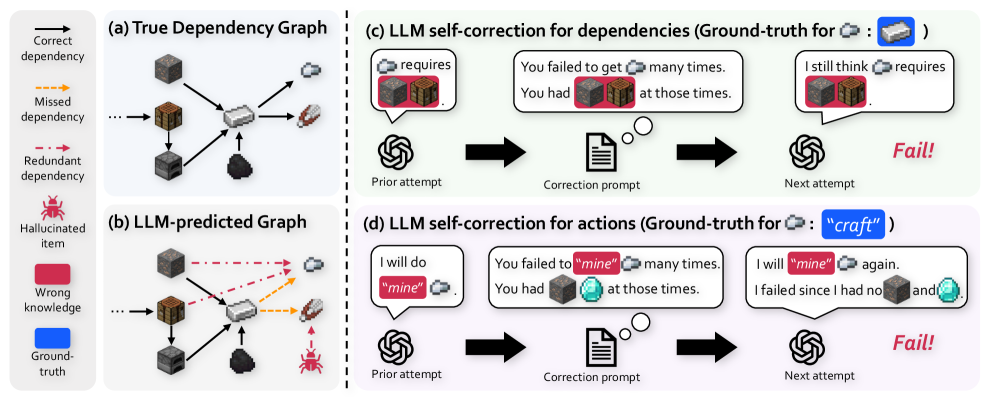
## Diagram: LLM Dependency and Action Self-Correction Failure Modes
### Overview
This technical diagram illustrates the failure modes of Large Language Models (LLMs) when attempting to self-correct their reasoning about dependencies and actions, using a crafting/mining scenario (likely from a game like Minecraft). It contrasts a ground-truth dependency graph with an LLM's flawed prediction and shows how correction prompts fail to fix the errors. The diagram is divided into four main panels: (a) True Dependency Graph, (b) LLM-predicted Graph, (c) LLM self-correction for dependencies, and (d) LLM self-correction for actions.
### Components/Axes
The diagram is organized into a 2x2 grid with a shared legend on the far left.
**Legend (Leftmost Column):**
* **Correct dependency:** Solid black arrow.
* **Missed dependency:** Dashed orange arrow.
* **Redundant dependency:** Dashed red arrow.
* **Hallucinated item:** Red spider icon.
* **Wrong knowledge:** Red rounded rectangle background.
* **Ground-truth:** Blue rounded rectangle background.
**Panel (a) True Dependency Graph (Top-Left):**
* **Title:** "(a) True Dependency Graph"
* **Components:** A network of item icons connected by solid black arrows (correct dependencies).
* Items include: a log, a plank, a crafting table, sticks, a wooden pickaxe, cobblestone, an iron ore, an iron ingot, and a stone pickaxe.
* The flow shows dependencies required to craft items (e.g., log → plank → crafting table).
**Panel (b) LLM-predicted Graph (Bottom-Left):**
* **Title:** "(b) LLM-predicted Graph"
* **Components:** The same set of item icons as in (a), but with different connections.
* **Solid black arrows:** Some correct dependencies are present.
* **Dashed orange arrows (Missed dependency):** Several required dependencies are missing (e.g., from iron ore to iron ingot).
* **Dashed red arrows (Redundant dependency):** Incorrect, unnecessary dependencies are added (e.g., from cobblestone to wooden pickaxe).
* **Hallucinated item:** A red spider icon appears, connected by a dashed red arrow to the stone pickaxe, indicating the LLM invented a non-existent requirement.
**Panel (c) LLM self-correction for dependencies (Top-Right):**
* **Title:** "(c) LLM self-correction for dependencies (Ground-truth for [Iron Ingot Icon]: [Iron Ore Icon] )"
* **Process Flow (Left to Right):**
1. **Prior attempt:** An LLM icon (spiral) with a speech bubble: "requires [Iron Ingot Icon] [Iron Ore Icon]". The "[Iron Ore Icon]" has a red background (Wrong knowledge).
2. **Correction prompt:** An arrow points to a document icon with a thought bubble. The text reads: "You failed to get [Iron Ingot Icon] many times. You had [Iron Ore Icon] [Cobblestone Icon] at those times." The "[Iron Ore Icon]" and "[Cobblestone Icon]" have red backgrounds.
3. **Next attempt:** An arrow points to another LLM icon with a speech bubble: "I still think [Iron Ingot Icon] requires [Iron Ore Icon] [Cobblestone Icon]". Both item icons have red backgrounds.
4. **Outcome:** The word "Fail!" in red, italic text.
**Panel (d) LLM self-correction for actions (Bottom-Right):**
* **Title:** "(d) LLM self-correction for actions (Ground-truth for [Iron Ingot Icon]: "craft" )"
* **Process Flow (Left to Right):**
1. **Prior attempt:** An LLM icon with a speech bubble: "I will do "mine" [Iron Ingot Icon]". The word "mine" has a red background (Wrong knowledge).
2. **Correction prompt:** An arrow points to a document icon. The text reads: "You failed to "mine" [Iron Ingot Icon] many times. You had [Cobblestone Icon] [Diamond Icon] at those times." The words "mine" and the item icons have red backgrounds.
3. **Next attempt:** An arrow points to another LLM icon with a speech bubble: "I will "mine" [Iron Ingot Icon] again. I failed since I had no [Cobblestone Icon] and [Diamond Icon]". The word "mine" and the item icons have red backgrounds.
4. **Outcome:** The word "Fail!" in red, italic text.
### Detailed Analysis
* **Graph Comparison:** The true graph (a) is a clean, directed acyclic graph. The LLM-predicted graph (b) is noisy, containing missed dependencies (orange), redundant dependencies (red), and a hallucinated item (spider).
* **Self-Correction Process (c & d):** Both processes follow the same three-step structure: flawed prior attempt → correction prompt with feedback → repeated flawed next attempt.
* **Text Transcription (Panel c):**
* Ground-truth label: "Ground-truth for [Iron Ingot Icon]: [Iron Ore Icon]"
* Prior attempt: "requires [Iron Ingot Icon] [Iron Ore Icon]"
* Correction prompt: "You failed to get [Iron Ingot Icon] many times. You had [Iron Ore Icon] [Cobblestone Icon] at those times."
* Next attempt: "I still think [Iron Ingot Icon] requires [Iron Ore Icon] [Cobblestone Icon]"
* **Text Transcription (Panel d):**
* Ground-truth label: "Ground-truth for [Iron Ingot Icon]: "craft""
* Prior attempt: "I will do "mine" [Iron Ingot Icon]"
* Correction prompt: "You failed to "mine" [Iron Ingot Icon] many times. You had [Cobblestone Icon] [Diamond Icon] at those times."
* Next attempt: "I will "mine" [Iron Ingot Icon] again. I failed since I had no [Cobblestone Icon] and [Diamond Icon]"
### Key Observations
1. **Persistent Error:** In both (c) and (d), the LLM repeats its initial错误 (wrong knowledge) in the "Next attempt" despite receiving corrective feedback.
2. **Error Types:** The LLM demonstrates two distinct failure modes: (1) incorrect dependency reasoning (c), and (2) incorrect action planning (e.g., using "mine" instead of "craft") (d).
3. **Hallucination:** Panel (b) explicitly shows the LLM inventing a dependency on a non-existent item (the spider).
4. **Correction Prompt Structure:** The prompts provide specific, instance-based feedback ("You failed... You had..."), but this is insufficient to alter the model's underlying incorrect belief.
### Interpretation
This diagram serves as a critical investigation into the limitations of LLM self-correction. It suggests that when an LLM's error stems from a fundamental misunderstanding of a system's rules (the true dependency graph) or a misclassification of required actions, simply providing feedback on past failures is ineffective. The model's "knowledge" or "reasoning process" appears rigid; it either cannot integrate the corrective information to update its internal model or defaults to reasserting its initial (flawed) prediction. This has significant implications for building reliable AI agents, highlighting that self-correction mechanisms may need to be supplemented with external verification tools or more structured knowledge representations to overcome deep-seated reasoning errors. The visual contrast between the clean true graph and the noisy predicted graph powerfully illustrates the gap between ground truth and LLM-generated understanding in procedural tasks.
DECODING INTELLIGENCE...