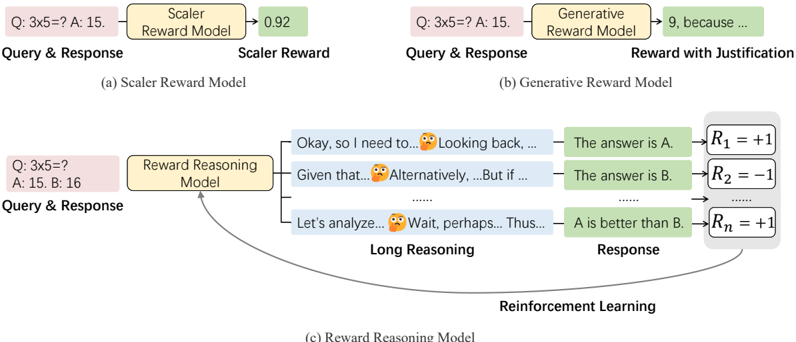
## Diagram: Reinforcement Learning Reward Models
### Overview
The diagram illustrates three distinct reward modeling approaches in reinforcement learning: (1) Scaler Reward Model, (2) Generative Reward Model, and (3) Reward Reasoning Model. Each model processes query-response pairs through different architectures to produce rewards, with varying levels of complexity and justification.
### Components/Axes
1. **Scaler Reward Model**
- Input: Query & Response (e.g., "Q: 3x5=? A: 15.")
- Process: Single-step evaluation through "Scaler Reward Model"
- Output: Scalar reward value (0.92)
2. **Generative Reward Model**
- Input: Query & Response (e.g., "Q: 3x5=? A: 15.")
- Process: Single-step evaluation through "Generative Reward Model"
- Output: Reward with justification (e.g., "9, because...")
3. **Reward Reasoning Model**
- Input: Query & Response (e.g., "Q: 3x5=? A: 15. B: 16")
- Process:
- Long Reasoning phase with multiple cognitive steps:
- "Okay, so I need to..."
- "Given that..."
- "Alternatively..."
- "Let's analyze..."
- Reinforcement Learning outputs:
- R₁ = +1 (for "The answer is A.")
- R₂ = -1 (for "The answer is B.")
- Rₙ = +1 (for "A is better than B.")
- Output: Final response with cumulative reward
### Detailed Analysis
- **Scaler Model**: Direct numerical evaluation with high confidence (0.92) but no reasoning trace.
- **Generative Model**: Combines numerical output with natural language justification, suggesting intermediate reasoning steps.
- **Reward Reasoning Model**:
- Explicitly models multi-step reasoning with cognitive uncertainty indicators (🤔 emojis)
- Implements reinforcement learning through sequential reward assignments (R₁, R₂, Rₙ)
- Demonstrates iterative refinement of responses through conflicting hypotheses
### Key Observations
1. **Complexity Gradient**: Models progress from simple scalar evaluation (0.92) to multi-step reasoning with explicit reinforcement learning components.
2. **Justification Mechanisms**:
- Generative Model provides post-hoc justification
- Reward Reasoning Model embeds justification within the reasoning process
3. **Uncertainty Representation**:
- Scaler Model shows high confidence (0.92)
- Reward Reasoning Model uses emojis and conflicting hypotheses to represent cognitive uncertainty
4. **Reinforcement Learning Integration**: Only the Reward Reasoning Model explicitly incorporates RL components (R₁, R₂, Rₙ)
### Interpretation
This diagram reveals a progression in reward modeling sophistication:
1. **Baseline Evaluation**: Scaler Model represents traditional, confidence-weighted scoring
2. **Interpretability Layer**: Generative Model adds natural language explanations to black-box evaluations
3. **Cognitive Architecture**: Reward Reasoning Model formalizes human-like reasoning through:
- Explicit hypothesis generation ("Alternatively...")
- Conflict resolution ("A is better than B.")
- Sequential reinforcement learning updates
The inclusion of emojis (🤔) in the Reward Reasoning Model suggests an attempt to model cognitive states during reasoning. The reinforcement learning components (R₁, R₂, Rₙ) indicate a dynamic adjustment mechanism where multiple reasoning paths are evaluated and rewarded independently before converging on a final response. This architecture appears designed to handle complex, multi-faceted decision-making tasks where simple scalar rewards are insufficient.