\n
## Bar Chart: Benchmark Comparison
### Overview
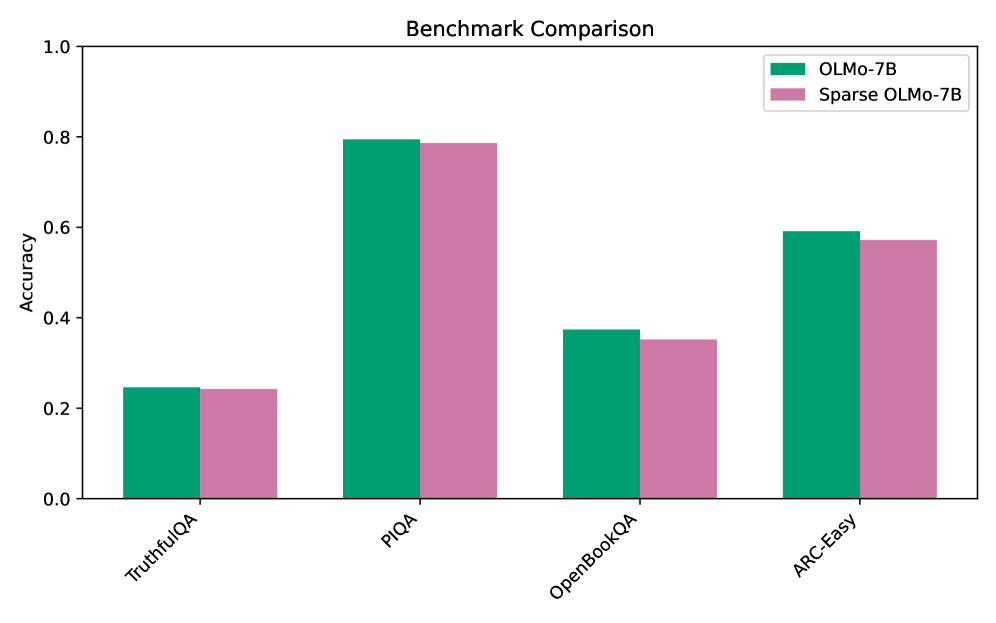
The image presents a bar chart comparing the accuracy of two models, OLMo-7B and Sparse OLMo-7B, across four different benchmarks: TruthfulQA, PIQA, OpenBookQA, and ARC-Easy. The chart visually represents the performance of each model on each benchmark using adjacent bars.
### Components/Axes
* **Title:** "Benchmark Comparison" (centered at the top)
* **X-axis:** Benchmark names: "TruthfulQA", "PIQA", "OpenBookQA", "ARC-Easy" (placed horizontally at the bottom)
* **Y-axis:** Accuracy (ranging from 0.0 to 1.0, placed vertically on the left)
* **Legend:** Located in the top-right corner.
* Green: "OLMo-7B"
* Purple/Pink: "Sparse OLMo-7B"
### Detailed Analysis
The chart consists of four groups of two bars, one for each benchmark.
* **TruthfulQA:**
* OLMo-7B (Green): Approximately 0.24 accuracy.
* Sparse OLMo-7B (Purple): Approximately 0.22 accuracy.
* **PIQA:**
* OLMo-7B (Green): Approximately 0.76 accuracy.
* Sparse OLMo-7B (Purple): Approximately 0.79 accuracy.
* **OpenBookQA:**
* OLMo-7B (Green): Approximately 0.34 accuracy.
* Sparse OLMo-7B (Purple): Approximately 0.41 accuracy.
* **ARC-Easy:**
* OLMo-7B (Green): Approximately 0.58 accuracy.
* Sparse OLMo-7B (Purple): Approximately 0.54 accuracy.
### Key Observations
* Sparse OLMo-7B generally outperforms OLMo-7B on PIQA and OpenBookQA.
* OLMo-7B outperforms Sparse OLMo-7B on TruthfulQA and ARC-Easy.
* The accuracy scores vary significantly across the different benchmarks, suggesting that the models' performance is benchmark-dependent.
* The difference in performance between the two models is relatively small for TruthfulQA, but more noticeable for PIQA and OpenBookQA.
### Interpretation
The data suggests that the Sparse OLMo-7B model exhibits stronger performance on benchmarks requiring reasoning and knowledge integration (PIQA, OpenBookQA), while the OLMo-7B model performs better on benchmarks focused on truthfulness and simpler reasoning (TruthfulQA, ARC-Easy). This could indicate that the sparsity applied in Sparse OLMo-7B enhances its ability to handle more complex tasks, but potentially at the cost of performance on tasks requiring strict factual recall. The varying performance across benchmarks highlights the importance of evaluating models on a diverse set of tasks to gain a comprehensive understanding of their capabilities. The relatively small differences in accuracy suggest that both models are performing at a comparable level overall, but their strengths lie in different areas. The choice of which model to use would depend on the specific application and the characteristics of the data it will be processing.