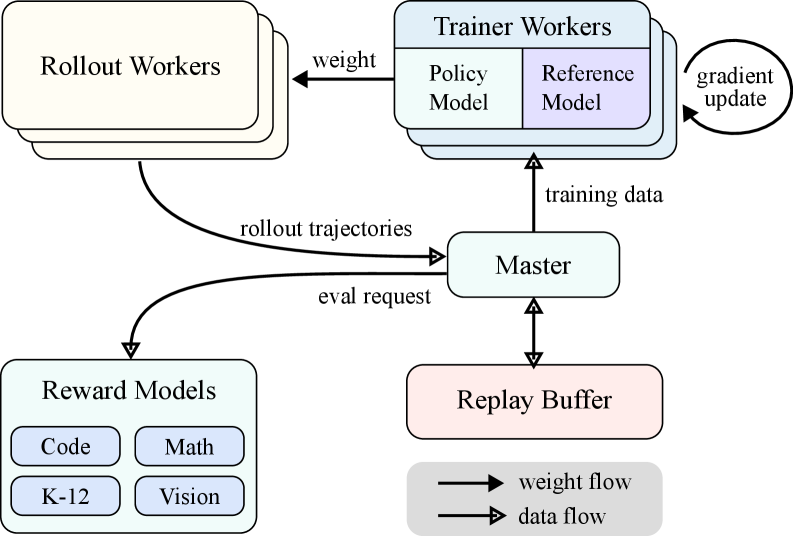
## Diagram: Distributed Reinforcement Learning System Architecture
### Overview
This diagram illustrates a distributed reinforcement learning (RL) system architecture with multiple components interacting through data and weight flows. The system includes Rollout Workers, Trainer Workers, a Master node, a Replay Buffer, and Reward Models for evaluation. Arrows indicate bidirectional communication between components, with explicit labels for data types (e.g., "rollout trajectories," "gradient update").
### Components/Axes
1. **Rollout Workers** (top-left cluster):
- Sends "rollout trajectories" to the Master.
- Receives "weight" updates from Trainer Workers.
2. **Trainer Workers** (middle cluster):
- Contains two sub-components:
- **Policy Model** (light blue): Primary model being trained.
- **Reference Model** (purple): Benchmark for comparison.
- Receives "training data" from the Master.
- Sends "gradient update" to the Master.
3. **Master** (central node):
- Coordinates interactions between components.
- Sends "training data" to Trainer Workers.
- Receives "rollout trajectories" from Rollout Workers.
- Sends "eval request" to Reward Models.
4. **Replay Buffer** (bottom-center):
- Stores experiences for training.
- Receives data from the Master and sends data back.
5. **Reward Models** (bottom-left cluster):
- Sub-categories:
- Code
- Math
- K-12
- Vision
- Evaluates trajectories via "eval request" from the Master.
### Detailed Analysis
- **Data Flow**:
- Rollout trajectories flow from Rollout Workers → Master → Replay Buffer.
- Training data flows from Master → Trainer Workers → Replay Buffer.
- Gradient updates flow from Trainer Workers → Master.
- **Weight Flow**:
- Weights flow from Trainer Workers → Rollout Workers.
- **Key Connections**:
- The Master acts as a central hub, coordinating data and weight exchanges.
- Reward Models provide evaluation feedback to the Master, which influences training.
### Key Observations
1. **Bidirectional Communication**:
- Rollout Workers and Trainer Workers exchange weights and trajectories, indicating a decentralized training loop.
2. **Hierarchical Structure**:
- The Master centralizes control, while Reward Models operate at the evaluation layer.
3. **Replay Buffer Role**:
- Acts as a memory for past experiences, critical for stable RL training.
### Interpretation
This architecture resembles a multi-agent RL system with centralized training coordination. The Rollout Workers generate experiences, which are evaluated by Reward Models and used to update the Policy Model via gradient descent. The Reference Model likely serves as a baseline for policy improvement. The Replay Buffer ensures data efficiency by reusing past experiences. The system’s design emphasizes scalability (via distributed workers) and stability (via experience replay), typical of modern RL frameworks like A3C or PPO.
No numerical data or trends are present, as the diagram focuses on structural relationships rather than quantitative metrics.