## Heatmap: Probability of Words in a Sequence
### Overview
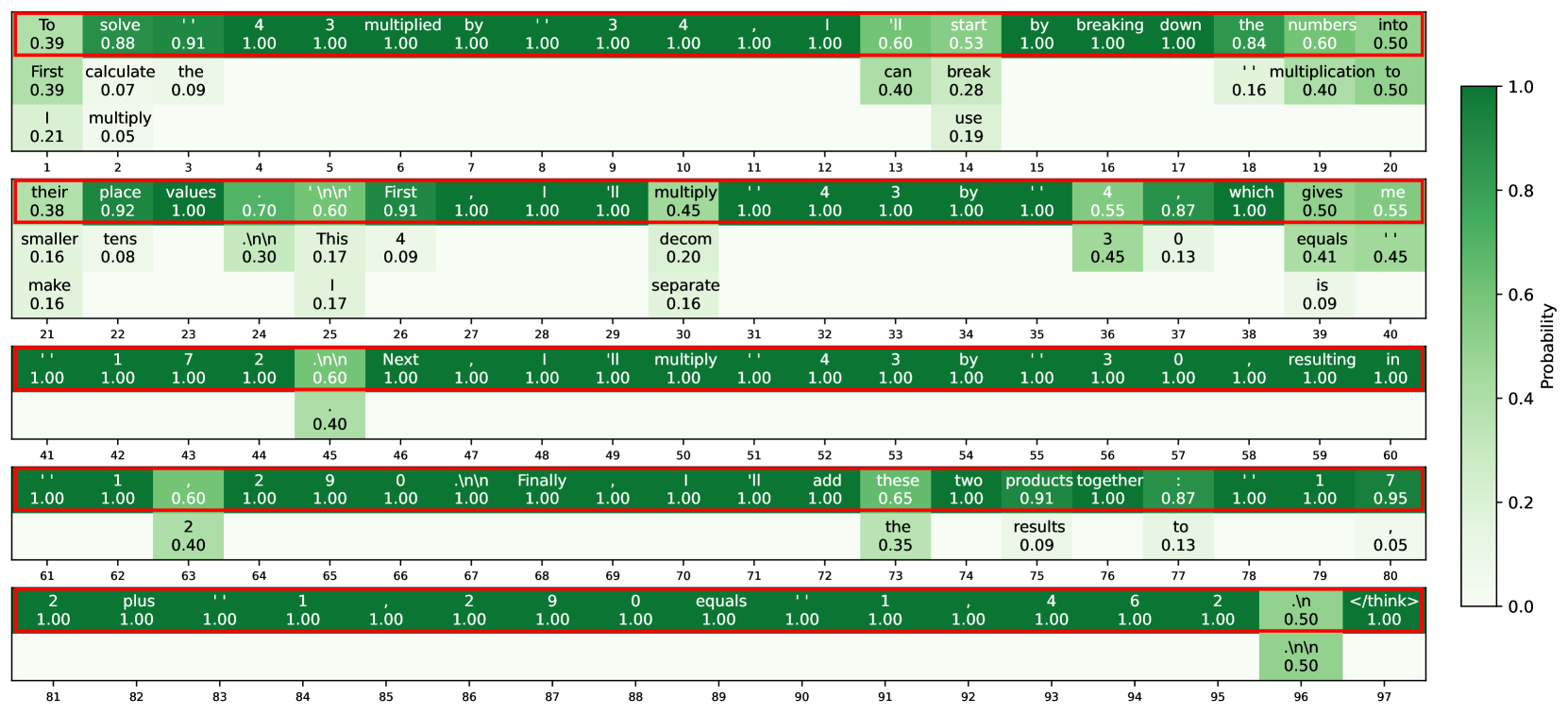
The image is a heatmap displaying the probability of different words appearing in a sequence. The heatmap is arranged in rows, with each row representing a step in the sequence. The color intensity represents the probability, ranging from 0.0 (dark green) to 1.0 (light green). The x-axis is numbered from 1 to 97, representing the position in the sequence.
### Components/Axes
* **X-axis:** Numbers 1 to 97, representing the position of the word in the sequence.
* **Y-axis:** Implicitly defined by the rows of words. Each row represents a different set of word choices at a particular step in the sequence.
* **Color Scale (Probability):** A vertical color bar on the right side of the image indicates the probability scale. Dark green corresponds to a probability of 0.0, and light green corresponds to a probability of 1.0.
### Detailed Analysis or ### Content Details
Here's a breakdown of the words and their probabilities at different positions:
* **Row 1 (Positions 1-7):**
* "To": 0.39
* "solve": 0.88
* "'": 0.91
* "4": 1.00
* "3": 1.00
* "multiplied": 1.00
* "by": 1.00
* **Row 2 (Positions 1-3, 14-17):**
* "First": 0.39
* "calculate": 0.07
* "the": 0.09
* "I": 1.00
* "start": 0.60
* "by": 0.53
* "breaking": 1.00
* "down": 1.00
* **Row 3 (Positions 1, 13, 18-20):**
* "I": 0.21
* "multiply": 0.05
* "''": 0.60
* "can": 0.40
* "break": 0.28
* "the": 0.84
* "numbers": 0.60
* "into": 0.50
* **Row 4 (Positions 13, 18-20):**
* "use": 0.19
* "''": 0.16
* "multiplication": 0.40
* "to": 0.50
* **Row 5 (Positions 1-7):**
* "their": 0.38
* "place": 0.92
* "values": 1.00
* ".\n\n": 0.70
* "'\\n\\n'": 0.60
* "First": 0.91
* "'": 1.00
* **Row 6 (Positions 1-4, 29-31):**
* "smaller": 0.16
* "tens": 0.08
* ".\\n\\n": 0.30
* "This": 0.17
* "4": 0.09
* "''": 1.00
* "decom": 0.20
* "separate": 0.16
* **Row 7 (Positions 1, 36-40):**
* "make": 0.16
* "I": 0.17
* "3": 0.45
* "0": 0.13
* "which": 1.00
* "gives": 0.50
* "me": 0.55
* **Row 8 (Positions 39-40):**
* "equals": 0.41
* "''": 0.45
* **Row 9 (Positions 39-40):**
* "is": 0.09
* **Row 10 (Positions 21-27):**
* "'": 1.00
* "1": 1.00
* "7": 1.00
* "2": 1.00
* ".\\n\\n": 0.60
* "Next": 1.00
* "'": 1.00
* **Row 11 (Position 25):**
* ".": 0.40
* **Row 12 (Positions 38-40):**
* "resulting": 1.00
* "in": 1.00
* **Row 13 (Positions 41-47):**
* "'": 1.00
* "1": 1.00
* "2": 0.60
* "9": 1.00
* "0": 1.00
* ".\\n\\n": 1.00
* "Finally": 1.00
* **Row 14 (Positions 43):**
* "2": 0.40
* **Row 15 (Positions 51-57):**
* "''": 1.00
* "add": 1.00
* "these": 0.65
* "two": 1.00
* "products": 0.91
* "together": 1.00
* ":": 0.87
* **Row 16 (Positions 53-54, 59-60):**
* "the": 0.35
* "results": 0.09
* "to": 0.13
* "1": 1.00
* "7": 0.95
* **Row 17 (Positions 61-63):**
* "2": 1.00
* "plus": 1.00
* "'": 1.00
* **Row 18 (Positions 73-77):**
* "1": 1.00
* "2": 1.00
* "9": 1.00
* "0": 1.00
* "equals": 1.00
* "'": 1.00
* **Row 19 (Positions 71-72, 79-80):**
* "1": 1.00
* "4": 1.00
* "6": 1.00
* "2": 0.50
* ".\\n": 0.50
* "</think>": 1.00
* **Row 20 (Position 96):**
* ".\\n\\n": 0.50
### Key Observations
* Many words have a probability of 1.0, indicating a high certainty of their occurrence at those positions.
* Some words have very low probabilities (close to 0.0), suggesting they are unlikely to appear in those positions.
* The heatmap provides a visual representation of the likelihood of different words in a sequence, which could be useful for language modeling or sequence prediction tasks.
### Interpretation
The heatmap visualizes the probability distribution of words in a sequence, likely generated by a language model or a similar predictive algorithm. The high probabilities (close to 1.0) indicate strong predictions for those words at specific positions, while low probabilities suggest unlikely word choices. This type of visualization is useful for understanding the model's confidence and potential errors in sequence generation. The presence of ".\\n" and other special characters suggests that the sequence might be related to code or structured text. The "\<think>" tag suggests a potential end-of-thought marker.