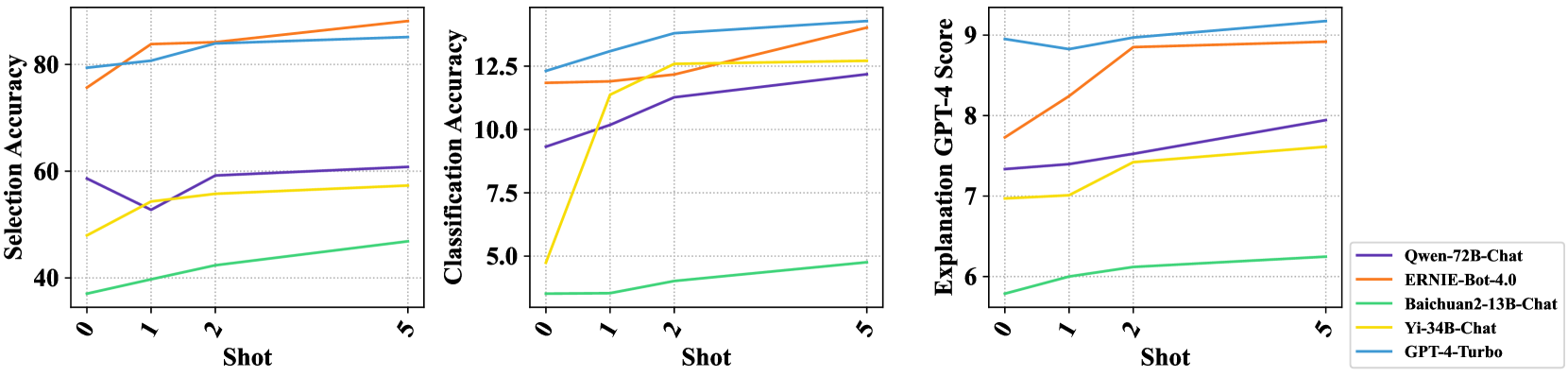
## Comparative Performance of AI Models Across Three Metrics
### Overview
The image displays three line charts arranged horizontally, comparing the performance of five different AI models across three distinct metrics as a function of "Shot" (likely few-shot learning examples). The charts share a common x-axis ("Shot") and a common legend, but have different y-axes representing different performance measures.
### Components/Axes
* **Common X-Axis (All Charts):** Labeled "Shot". The axis markers are at values 0, 1, 2, and 5.
* **Legend:** Located in the bottom-right corner of the third chart. It maps line colors to model names:
* Purple Line: `Qwen-72B-Chat`
* Orange Line: `ERNIE-Bot-4.0`
* Green Line: `Baichuan2-13B-Chat`
* Yellow Line: `Yi-34B-Chat`
* Blue Line: `GPT-4-Turbo`
* **Chart 1 (Left):**
* **Title/Y-Axis:** "Selection Accuracy"
* **Y-Axis Scale:** Ranges from approximately 40 to 90. Major gridlines are at 40, 60, 80.
* **Chart 2 (Center):**
* **Title/Y-Axis:** "Classification Accuracy"
* **Y-Axis Scale:** Ranges from approximately 5 to 14. Major gridlines are at 5.0, 7.5, 10.0, 12.5.
* **Chart 3 (Right):**
* **Title/Y-Axis:** "Explanation GPT-4 Score"
* **Y-Axis Scale:** Ranges from approximately 6 to 9. Major gridlines are at 6, 7, 8, 9.
### Detailed Analysis
**Chart 1: Selection Accuracy**
* **Trend Verification:** All lines show a general upward or stable trend as the number of shots increases from 0 to 5.
* **Data Points (Approximate):**
* **GPT-4-Turbo (Blue):** Starts high (~80 at 0-shot), increases slightly and plateaus around 85-86.
* **ERNIE-Bot-4.0 (Orange):** Starts around 76, increases sharply to ~84 at 1-shot, then continues a steady rise to ~88 at 5-shot.
* **Qwen-72B-Chat (Purple):** Starts around 59, dips to ~53 at 1-shot, recovers to ~60 at 2-shot, and ends near 61 at 5-shot.
* **Yi-34B-Chat (Yellow):** Starts around 48, increases steadily to ~58 at 5-shot.
* **Baichuan2-13B-Chat (Green):** Starts lowest at ~37, increases gradually to ~47 at 5-shot.
**Chart 2: Classification Accuracy**
* **Trend Verification:** All lines show an upward trend. The rate of increase varies significantly between models.
* **Data Points (Approximate):**
* **GPT-4-Turbo (Blue):** Highest throughout. Starts ~12.2, rises steadily to ~13.8 at 5-shot.
* **ERNIE-Bot-4.0 (Orange):** Starts ~11.8, remains flat to 1-shot, then increases sharply to ~13.5 at 5-shot.
* **Yi-34B-Chat (Yellow):** Shows the most dramatic initial increase. Starts very low (~4.8), jumps to ~11.2 at 1-shot, then plateaus around 12.6.
* **Qwen-72B-Chat (Purple):** Starts ~9.2, increases steadily to ~12.2 at 5-shot.
* **Baichuan2-13B-Chat (Green):** Lowest throughout. Starts ~3.5, increases slowly to ~4.8 at 5-shot.
**Chart 3: Explanation GPT-4 Score**
* **Trend Verification:** All lines show a general upward trend, with some models plateauing after an initial rise.
* **Data Points (Approximate):**
* **GPT-4-Turbo (Blue):** Highest and most stable. Hovers around 9.0 across all shots.
* **ERNIE-Bot-4.0 (Orange):** Starts ~7.7, increases to ~8.9 at 2-shot, and plateaus there.
* **Qwen-72B-Chat (Purple):** Starts ~7.3, increases steadily to ~8.0 at 5-shot.
* **Yi-34B-Chat (Yellow):** Starts ~7.0, increases to ~7.6 at 5-shot.
* **Baichuan2-13B-Chat (Green):** Lowest throughout. Starts ~5.8, increases slowly to ~6.2 at 5-shot.
### Key Observations
1. **Consistent Hierarchy:** `GPT-4-Turbo` (Blue) is the top performer across all three metrics at nearly every shot level.
2. **Strong Improver:** `ERNIE-Bot-4.0` (Orange) shows significant gains with more shots, particularly in Selection and Classification Accuracy, often closing the gap with the top model.
3. **Variable Starting Points:** Models have vastly different zero-shot performance. For example, in Classification Accuracy, `Yi-34B-Chat` starts extremely low but improves dramatically with one shot.
4. **Consistent Laggard:** `Baichuan2-13B-Chat` (Green) consistently performs the worst across all metrics and shot counts, though it still shows improvement.
5. **Metric Sensitivity:** The relative ranking of models (excluding the top and bottom) shifts between metrics. For instance, `Qwen-72B-Chat` outperforms `Yi-34B-Chat` in Selection Accuracy but underperforms it in Classification Accuracy after 1-shot.
### Interpretation
The data demonstrates the impact of few-shot learning (increasing "Shot" count) on the performance of various large language models. The consistent upward trends indicate that providing examples generally helps all models improve on these tasks.
The charts reveal a clear performance tier: `GPT-4-Turbo` operates at a high, stable level, suggesting robustness. `ERNIE-Bot-4.0` and `Yi-34B-Chat` are highly responsive to in-context learning, with `Yi-34B-Chat` showing a particularly steep learning curve for classification. `Qwen-72B-Chat` shows moderate, steady improvement. `Baichuan2-13B-Chat`'s lower performance may indicate a smaller model capacity or less optimization for these specific tasks.
The divergence in model rankings across metrics (Selection vs. Classification vs. Explanation) suggests that model capabilities are not uniform. A model strong at selecting information may not be equally strong at classifying it or generating high-quality explanations, highlighting the importance of multi-faceted evaluation. The "Explanation GPT-4 Score" being evaluated by GPT-4 itself introduces a potential bias, where models more similar to GPT-4 in style may score higher.