## Line Chart: Surprisal vs. Training Steps
### Overview
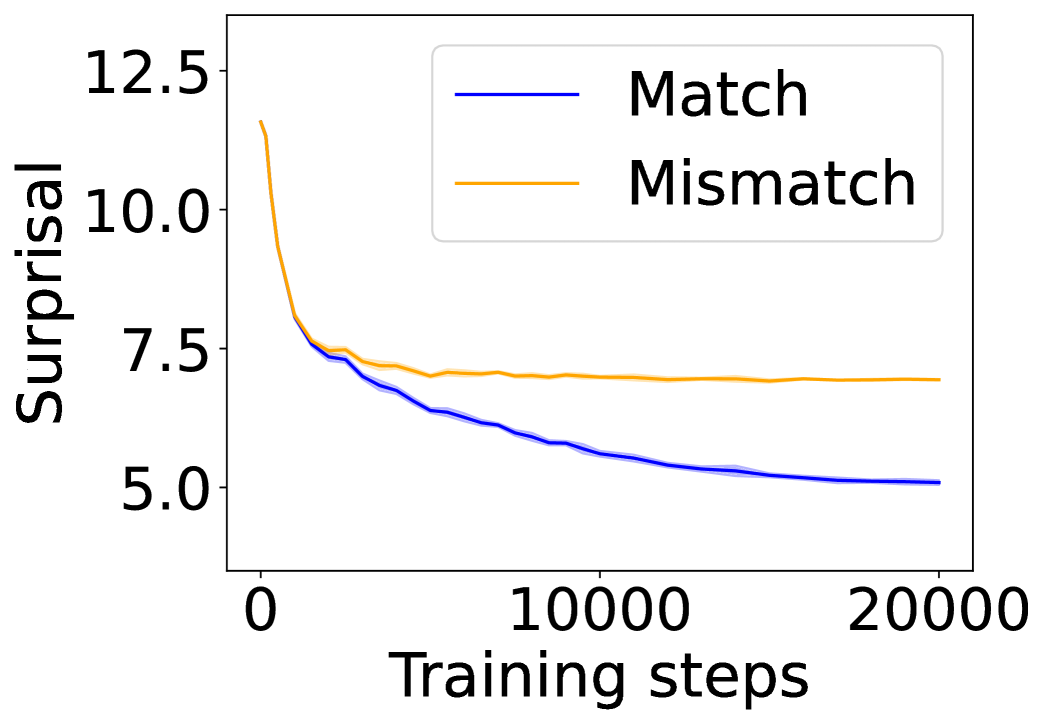
The image is a line chart comparing the surprisal values of "Match" and "Mismatch" conditions over 20,000 training steps. The chart shows how surprisal decreases with training, with "Match" consistently exhibiting lower surprisal than "Mismatch."
### Components/Axes
* **X-axis:** Training steps, ranging from 0 to 20,000 in increments of 10,000.
* **Y-axis:** Surprisal, ranging from 5.0 to 12.5 in increments of 2.5.
* **Legend:** Located in the top-right corner, it identifies the two data series:
* Blue line: "Match"
* Orange line: "Mismatch"
### Detailed Analysis
* **Match (Blue):**
* Trend: The surprisal starts at approximately 8.0 and decreases rapidly initially, then plateaus around 5.0 after approximately 10,000 training steps.
* Data Points:
* 0 training steps: ~8.0 surprisal
* 10,000 training steps: ~5.2 surprisal
* 20,000 training steps: ~5.0 surprisal
* **Mismatch (Orange):**
* Trend: The surprisal starts at approximately 12.0 and decreases rapidly initially, then plateaus around 7.0 after approximately 10,000 training steps.
* Data Points:
* 0 training steps: ~12.0 surprisal
* 10,000 training steps: ~7.2 surprisal
* 20,000 training steps: ~7.0 surprisal
### Key Observations
* Both "Match" and "Mismatch" conditions show a significant decrease in surprisal during the initial training phase.
* The "Match" condition consistently exhibits lower surprisal values compared to the "Mismatch" condition throughout the training process.
* The rate of decrease in surprisal slows down considerably after approximately 10,000 training steps for both conditions.
### Interpretation
The chart suggests that as the model trains, it becomes better at predicting both "Match" and "Mismatch" scenarios, as indicated by the decreasing surprisal values. The lower surprisal for "Match" indicates that the model finds "Match" scenarios more predictable or less surprising than "Mismatch" scenarios. The plateauing of the curves suggests that the model reaches a point of diminishing returns in terms of learning, where further training does not significantly reduce surprisal.