\n
## Line Chart: Filtering based on Process vs. Outcome
### Overview
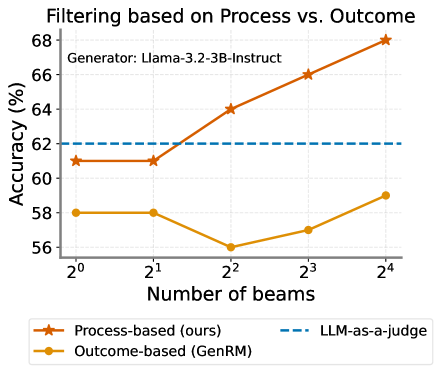
This is a line chart comparing the accuracy of two filtering methods ("Process-based" and "Outcome-based") against a baseline ("LLM-as-a-judge") as the number of beams increases. The chart is generated using the "Llama-3.2-3B-Instruct" model, as noted in the top-left corner of the plot area.
### Components/Axes
* **Title:** "Filtering based on Process vs. Outcome"
* **Generator Label:** "Generator: Llama-3.2-3B-Instruct" (positioned in the top-left of the chart area).
* **Y-Axis:**
* **Label:** "Accuracy (%)"
* **Scale:** Linear, ranging from 56 to 68, with major tick marks at 56, 58, 60, 62, 64, 66, 68.
* **X-Axis:**
* **Label:** "Number of beams"
* **Scale:** Logarithmic base 2, with categorical tick marks at 2⁰ (1), 2¹ (2), 2² (4), 2³ (8), and 2⁴ (16).
* **Legend:** Positioned at the bottom of the chart.
* **Orange line with star markers:** "Process-based (ours)"
* **Yellow line with circle markers:** "Outcome-based (GenRM)"
* **Blue dashed line:** "LLM-as-a-judge"
### Detailed Analysis
**Data Series and Points:**
1. **Process-based (ours) - Orange line with star markers:**
* **Trend:** Shows a consistent, strong upward trend as the number of beams increases.
* **Data Points (Approximate):**
* At 2⁰ beams: ~61%
* At 2¹ beams: ~61%
* At 2² beams: ~64%
* At 2³ beams: ~66%
* At 2⁴ beams: ~68%
2. **Outcome-based (GenRM) - Yellow line with circle markers:**
* **Trend:** Shows a non-monotonic trend. It starts flat, dips significantly at 2² beams, then recovers and increases.
* **Data Points (Approximate):**
* At 2⁰ beams: ~58%
* At 2¹ beams: ~58%
* At 2² beams: ~56% (lowest point)
* At 2³ beams: ~57%
* At 2⁴ beams: ~59%
3. **LLM-as-a-judge - Blue dashed line:**
* **Trend:** Constant, horizontal line.
* **Value:** Fixed at 62% accuracy across all beam numbers.
### Key Observations
* The "Process-based (ours)" method demonstrates superior scaling, with accuracy improving significantly as more beams are used. It surpasses the "LLM-as-a-judge" baseline between 2¹ and 2² beams.
* The "Outcome-based (GenRM)" method performs worse than the baseline at all tested beam counts. Its performance notably degrades at 2² beams before a partial recovery.
* The "LLM-as-a-judge" serves as a static performance benchmark at 62%.
* The performance gap between the two active methods widens considerably as the number of beams increases, from a ~3% difference at 2⁰ beams to a ~9% difference at 2⁴ beams.
### Interpretation
The chart suggests that the "Process-based" filtering approach is more effective and benefits more from increased computational resources (represented by a higher number of beams) compared to the "Outcome-based" approach for the given task and model. The consistent upward trend indicates that the process-based method effectively utilizes the additional beams to refine its outputs and improve accuracy.
In contrast, the outcome-based method shows instability, with a performance drop at a moderate beam count (4), suggesting it may struggle with certain search configurations or that its reward model (GenRM) is less robust. Its final accuracy at 16 beams remains below the simple, static baseline.
The key takeaway is that for this specific application using Llama-3.2-3B-Instruct, investing in more beams yields clear returns when using the proposed process-based filtering, while the alternative outcome-based method does not justify the added computational cost over the baseline judge.