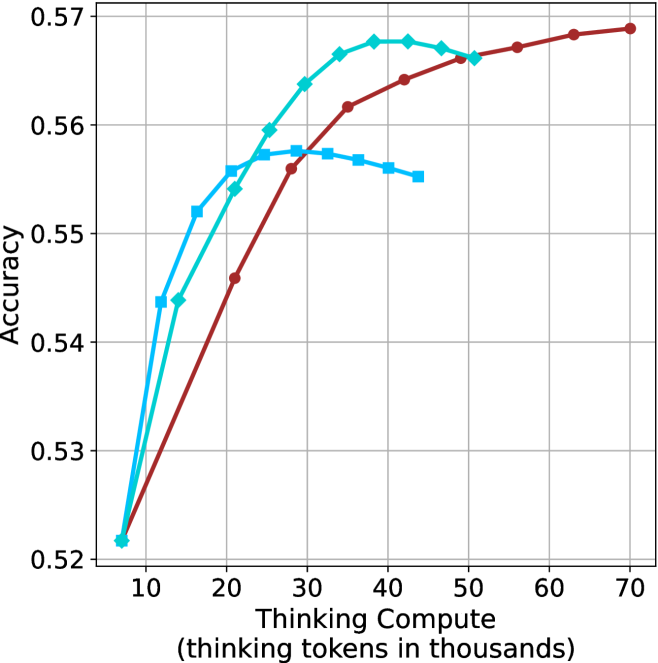
## Line Chart: Accuracy vs. Thinking Compute
### Overview
This image is a line chart illustrating the relationship between "Thinking Compute" (measured in thousands of thinking tokens) and model "Accuracy." The chart displays three distinct data series, each represented by a different color and marker shape. All three series originate from a common baseline point. There is no legend provided in the image to identify the specific models or configurations associated with each line.
### Components/Axes
* **Y-Axis:** Labeled "Accuracy." The scale ranges from 0.52 to 0.57, with major grid lines at 0.01 intervals.
* **X-Axis:** Labeled "Thinking Compute (thinking tokens in thousands)." The scale ranges from 10 to 70, with a starting point at approximately 7.
* **Data Series (Visual Identification):**
* **Series A (Dark Red/Maroon):** Circular markers.
* **Series B (Medium Blue/Teal):** Diamond markers.
* **Series C (Light Blue/Sky Blue):** Square markers.
### Detailed Analysis
All three data series originate from a shared starting point at approximately **(7, 0.522)**.
**1. Series A (Dark Red, Circles)**
* **Trend:** This series shows a consistent, monotonic upward trend throughout the entire range of the X-axis. It does not show signs of degradation.
* **Data Points (Approximate):**
* Starts at (7, 0.522).
* (21, 0.546)
* (28, 0.556)
* (35, 0.562)
* (42, 0.564)
* (50, 0.566)
* (57, 0.567)
* (63, 0.568)
* (70, 0.569)
**2. Series B (Medium Blue, Diamonds)**
* **Trend:** This series rises steeply, outperforming the other two lines between 20k and 45k tokens. It reaches a peak and then begins a slight decline.
* **Data Points (Approximate):**
* Starts at (7, 0.522).
* (14, 0.544)
* (21, 0.554)
* (25, 0.559)
* (28, 0.564)
* (32, 0.566)
* (36, 0.567)
* (41, 0.568)
* (45, 0.568)
* (50, 0.566)
**3. Series C (Light Blue, Squares)**
* **Trend:** This series rises the fastest initially but plateaus and begins to decline the earliest, suggesting an "overthinking" penalty.
* **Data Points (Approximate):**
* Starts at (7, 0.522).
* (11, 0.544)
* (16, 0.552)
* (21, 0.556)
* (28, 0.558)
* (32, 0.558)
* (36, 0.557)
* (40, 0.556)
* (44, 0.555)
### Key Observations
* **Shared Baseline:** All models begin with identical accuracy at the lowest compute level.
* **Performance Divergence:** The models diverge significantly after approximately 15k tokens.
* **Overthinking/Overfitting:** Both the Light Blue (squares) and Medium Blue (diamonds) series exhibit a "hump" shape, where accuracy increases with compute up to a point, then decreases. This is a classic indicator of overthinking, where additional compute tokens introduce noise or irrelevant information that degrades performance.
* **Robustness:** The Dark Red (circles) series is the most robust, continuing to gain accuracy even at the highest compute levels (70k tokens), suggesting it is the most compute-efficient or best-tuned model configuration.
### Interpretation
This chart demonstrates the "compute-optimal" scaling behavior of different model configurations.
* **The "Light Blue" model** is likely a smaller or less capable model that reaches its maximum utility quickly (around 30k tokens) and then suffers from diminishing returns.
* **The "Medium Blue" model** is more capable, scaling effectively up to 45k tokens before performance degradation sets in.
* **The "Dark Red" model** appears to be the most sophisticated or best-trained, as it continues to improve accuracy as compute increases, showing no signs of the "overthinking" penalty within the observed range.
This data is critical for determining the optimal "thinking budget" for a given model; allocating more tokens than the peak of the curve is not only wasteful but actively harmful to the model's accuracy.