\n
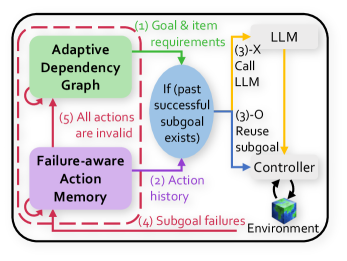
## Diagram: LLM-Based Agent Control System with Failure-Aware Memory
### Overview
The image is a technical system diagram illustrating a control flow for an AI agent (likely using a Large Language Model) that manages tasks through subgoals, incorporates memory of past failures, and adapts its internal dependency graph. The diagram uses color-coded components, numbered flow arrows, and a dashed boundary to define the system's scope.
### Components/Axes
The diagram is contained within a rounded rectangle with a **dashed red border**. The primary components are:
1. **Adaptive Dependency Graph** (Green box, top-left): Represents a dynamic model of task dependencies.
2. **Failure-aware Action Memory** (Purple box, bottom-left): Stores historical data on actions and their outcomes.
3. **Decision Node** (Blue oval, center): Contains the conditional logic: `If (past successful subgoal exists)`.
4. **LLM** (Grey cloud, top-right): The Large Language Model, acting as the high-level planner or reasoner.
5. **Controller** (White box, bottom-right): Executes commands or manages the interface with the environment.
6. **Environment** (3D cube icon, bottom-right): The external world or system the agent interacts with.
**Flow Arrows (Numbered Steps):**
* **(1) Goal & item requirements**: Green arrow from **LLM** to the **Decision Node**.
* **(2) Action history**: Purple arrow from **Failure-aware Action Memory** to the **Decision Node**.
* **(3)-X Call LLM**: Orange arrow from the **Decision Node** to the **LLM**.
* **(3)-O Reuse subgoal**: Blue arrow from the **Decision Node** to the **Controller**.
* **(4) Subgoal failures**: Red arrow from the **Environment** back to **Failure-aware Action Memory**.
* **(5) All actions are invalid**: Red arrow from **Failure-aware Action Memory** to the **Adaptive Dependency Graph**.
### Detailed Analysis
The diagram outlines a cyclical, feedback-driven process:
1. **Initialization**: The process begins with the **LLM** providing **(1) Goal & item requirements** to the central decision node.
2. **Context Gathering**: The decision node simultaneously receives **(2) Action history** from the **Failure-aware Action Memory**.
3. **Decision Point**: At the blue oval, the system checks: `If (past successful subgoal exists)`.
* **Path (3)-X**: If the condition is **false** (no successful past subgoal), it triggers **Call LLM**, sending a request back to the LLM for new planning.
* **Path (3)-O**: If the condition is **true**, it triggers **Reuse subgoal**, sending a command directly to the **Controller** for execution.
4. **Execution & Feedback**: The **Controller** acts upon the **Environment**. Outcomes, specifically failures, are fed back as **(4) Subgoal failures** to update the **Failure-aware Action Memory**.
5. **Adaptation**: If the memory determines that **(5) All actions are invalid** for a given context, it signals the **Adaptive Dependency Graph** to update its structure, presumably to avoid repeating failed pathways.
### Key Observations
* **Dual-Path Control**: The system has a clear branching logic based on historical success, creating a fast path (reuse) and a slow path (re-plan).
* **Centralized Memory**: The **Failure-aware Action Memory** is a critical hub, receiving failure data and providing history to inform both the immediate decision and long-term adaptation.
* **Explicit Failure Loop**: There is a dedicated, labeled feedback loop **(4)** for failures, highlighting that learning from errors is a core design principle.
* **Adaptation Trigger**: The condition for updating the dependency graph **(5)** is stringent—"All actions are invalid"—suggesting the graph changes only upon comprehensive failure, not single instances.
### Interpretation
This diagram depicts a sophisticated agent architecture designed for resilience and efficiency in sequential decision-making tasks. The core innovation is the tight integration of a **failure-aware memory** that directly influences both short-term action selection (via the decision node) and long-term strategy (via the adaptive graph).
The system prioritizes efficiency by reusing successful subgoals **(3)-O**, avoiding costly re-planning by the LLM. However, it remains robust by constantly checking action history and explicitly logging failures **(4)**. The most significant adaptation—modifying the dependency graph **(5)**—is reserved for scenarios where the current action repertoire is entirely exhausted, indicating a conservative approach to altering the core task model.
The flow suggests an agent that learns online from its interaction history, becoming more efficient by caching successes and more reliable by systematically recording and adapting to failures. The dashed red boundary implies this entire process is encapsulated as a single module or system.