\n
## Bar Chart: Accuracy at Eval Length = 512 on Copying
### Overview
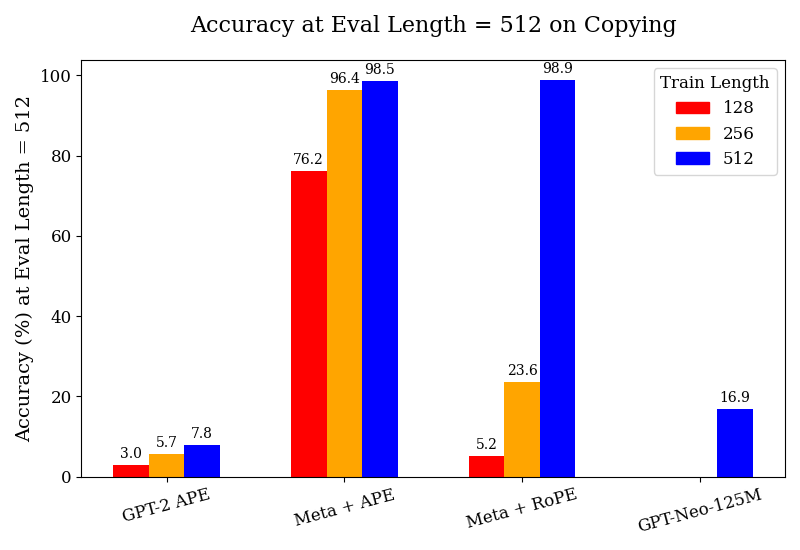
This is a grouped bar chart comparing the accuracy (in percentage) of four different language models or model configurations on a "copying" task, evaluated at a sequence length of 512. The performance is broken down by three different training sequence lengths (128, 256, and 512 tokens).
### Components/Axes
* **Title:** "Accuracy at Eval Length = 512 on Copying"
* **Y-Axis:** Label: "Accuracy (%) at Eval Length = 512". Scale: 0 to 100, with major ticks at intervals of 20.
* **X-Axis:** Lists four model configurations:
1. GPT-2 APE
2. Meta + APE
3. Meta + RoPE
4. GPT-Neo-125M
* **Legend:** Located in the top-right corner, titled "Train Length". It defines three color-coded categories:
* Red square: 128
* Orange square: 256
* Blue square: 512
### Detailed Analysis
The chart presents accuracy data for each model across the three training lengths. Values are annotated on top of each bar.
**1. GPT-2 APE:**
* **Trend:** Accuracy increases slightly with longer training length.
* **Data Points:**
* Train Length 128 (Red): ~3.0%
* Train Length 256 (Orange): ~5.7%
* Train Length 512 (Blue): ~7.8%
**2. Meta + APE:**
* **Trend:** Shows a strong, positive correlation between training length and accuracy. This group has the highest overall performance.
* **Data Points:**
* Train Length 128 (Red): ~76.2%
* Train Length 256 (Orange): ~96.4%
* Train Length 512 (Blue): ~98.5%
**3. Meta + RoPE:**
* **Trend:** Shows a very strong positive correlation. Performance is low for shorter training lengths but jumps dramatically for the longest training length.
* **Data Points:**
* Train Length 128 (Red): ~5.2%
* Train Length 256 (Orange): ~23.6%
* Train Length 512 (Blue): ~98.9%
**4. GPT-Neo-125M:**
* **Trend:** Only one data point is present.
* **Data Point:**
* Train Length 512 (Blue): ~16.9%
* (No bars are present for Train Lengths 128 or 256).
### Key Observations
1. **Dominant Performance:** The "Meta + APE" configuration achieves the highest accuracy across all training lengths, reaching near-perfect performance (~98.5%) when trained on sequences of length 512.
2. **Critical Training Length for Meta + RoPE:** The "Meta + RoPE" model shows a massive performance leap (from ~23.6% to ~98.9%) when the training length is increased from 256 to 512, matching the top performance of Meta + APE at that length.
3. **Baseline Performance:** "GPT-2 APE" shows consistently low accuracy (<8%), indicating poor performance on this copying task regardless of training length within the tested range.
4. **Missing Data:** "GPT-Neo-125M" only has a result for the 512 training length, which is modest (~16.9%). Its performance at shorter training lengths is not reported.
5. **General Trend:** For the three models with complete data, accuracy improves as the training sequence length increases.
### Interpretation
This chart demonstrates the critical importance of matching training sequence length to evaluation sequence length for certain model architectures on a copying task.
* **Architectural Efficacy:** The "Meta" architectures (likely referring to models using techniques from Meta AI) combined with either APE (Absolute Positional Encoding) or RoPE (Rotary Positional Embedding) significantly outperform the baseline GPT-2 APE model. This suggests the underlying "Meta" architecture or training method is superior for this specific task.
* **Positional Encoding Comparison:** At the longest training length (512), both APE and RoPE enable near-perfect copying (~98.5% vs. ~98.9%). However, their behavior differs at shorter training lengths. Meta + APE maintains relatively high accuracy even when trained on shorter sequences (76.2% at 128), while Meta + RoPE performs poorly until trained on sequences of the same length as the evaluation (5.2% at 128, jumping to 98.9% at 512). This implies RoPE may be more sensitive to the disparity between training and evaluation lengths.
* **Task Nature:** The "copying" task is a fundamental test of a model's ability to recall and reproduce input sequences. The near-perfect scores at 512 for the Meta models indicate they have successfully learned this pattern when provided with sufficient training context. The low scores for GPT-2 APE suggest it struggles with this form of long-range dependency or exact replication.
* **Implication:** For tasks requiring precise recall of long contexts, using a model architecture like the "Meta" variants and ensuring the training data includes sequences at least as long as the expected evaluation length is crucial for high performance.