## Diagram: States-conditioned Wan 2.2 DiT Block
### Overview
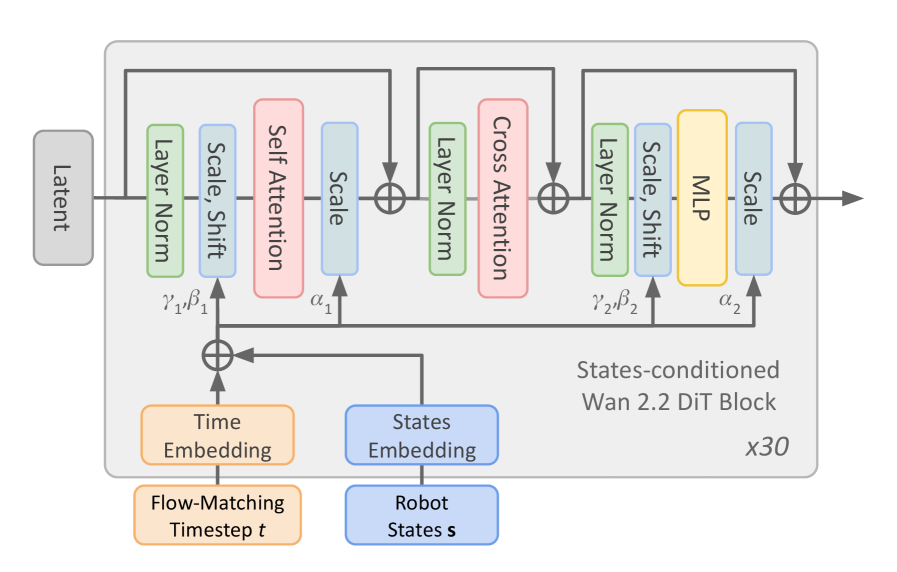
The image is a diagram illustrating the architecture of a States-conditioned Wan 2.2 Diffusion Transformer (DiT) Block. It shows the flow of data through various layers and operations, including Layer Normalization, Scale/Shift, Self Attention, Cross Attention, and MLP (Multi-Layer Perceptron). The diagram highlights the conditioning of the block on both time and robot states. The block is repeated 30 times.
### Components/Axes
* **Input:** Latent
* **Processing Blocks (repeated three times):**
* Layer Norm (Green)
* Scale, Shift (Blue)
* Self Attention (Red) or Cross Attention (Red) or MLP (Yellow)
* Scale (Blue)
* **Conditioning Inputs:**
* Time Embedding (Orange) - Flow-Matching Timestep t
* States Embedding (Blue) - Robot States s
* **Parameters:**
* γ1, β1 (associated with the first Layer Norm and Scale/Shift)
* α1 (associated with the first Scale)
* γ2, β2 (associated with the second Layer Norm and Scale/Shift)
* α2 (associated with the second Scale)
* **Output:** Output of the final Scale block.
* **Repetition:** x30 (Indicates the entire block is repeated 30 times)
### Detailed Analysis
The diagram illustrates a repeating block structure. The "Latent" input flows through a series of operations. Each block consists of a "Layer Norm" (green), followed by "Scale, Shift" (blue), then either "Self Attention" (red), "Cross Attention" (red), or "MLP" (yellow), and finally "Scale" (blue). The first block contains "Self Attention", the second contains "Cross Attention", and the third contains "MLP". The output of each block is fed back into the "Time Embedding" and "States Embedding" via an addition operation (⊕). The entire block is repeated 30 times, as indicated by "x30" at the bottom-right.
* **Latent Input:** The process begins with a "Latent" input, represented by a gray box on the top-left.
* **First Block:**
* The latent input flows into a "Layer Norm" block (green).
* The output of "Layer Norm" goes into a "Scale, Shift" block (blue).
* The output of "Scale, Shift" goes into a "Self Attention" block (red).
* The output of "Self Attention" goes into a "Scale" block (blue).
* **Second Block:**
* The output of the first "Scale" block flows into a "Layer Norm" block (green).
* The output of "Layer Norm" goes into a "Cross Attention" block (red).
* The output of "Cross Attention" goes into a "Scale" block (blue).
* **Third Block:**
* The output of the second "Scale" block flows into a "Layer Norm" block (green).
* The output of "Layer Norm" goes into a "Scale, Shift" block (blue).
* The output of "Scale, Shift" goes into an "MLP" block (yellow).
* The output of "MLP" goes into a "Scale" block (blue).
* **Conditioning:**
* "Time Embedding" (orange) and "States Embedding" (blue) provide conditioning signals.
* "Time Embedding" is associated with "Flow-Matching Timestep t".
* "States Embedding" is associated with "Robot States s".
* These embeddings are added (⊕) to the signal after the "Latent" input.
* **Parameters:**
* γ1, β1 are associated with the first "Layer Norm" and "Scale, Shift" blocks.
* α1 is associated with the first "Scale" block.
* γ2, β2 are associated with the third "Layer Norm" and "Scale, Shift" blocks.
* α2 is associated with the third "Scale" block.
### Key Observations
* The diagram illustrates a repeating block structure with variations in the attention mechanism (Self Attention, Cross Attention, and MLP).
* The conditioning inputs (Time Embedding and States Embedding) are crucial for the DiT block's functionality.
* The repetition factor (x30) indicates a deep architecture.
### Interpretation
The diagram represents a key component of a diffusion transformer model, specifically designed for tasks involving robot states and time-dependent data. The repeating block structure allows the model to learn complex relationships between the latent input, time, and robot states. The use of Self Attention, Cross Attention, and MLP within the blocks enables the model to capture different types of dependencies in the data. The conditioning on both time and robot states suggests that the model is designed to generate or process data that is dependent on both the current time step and the robot's state. The repetition of the block 30 times indicates a deep neural network, capable of learning intricate patterns.