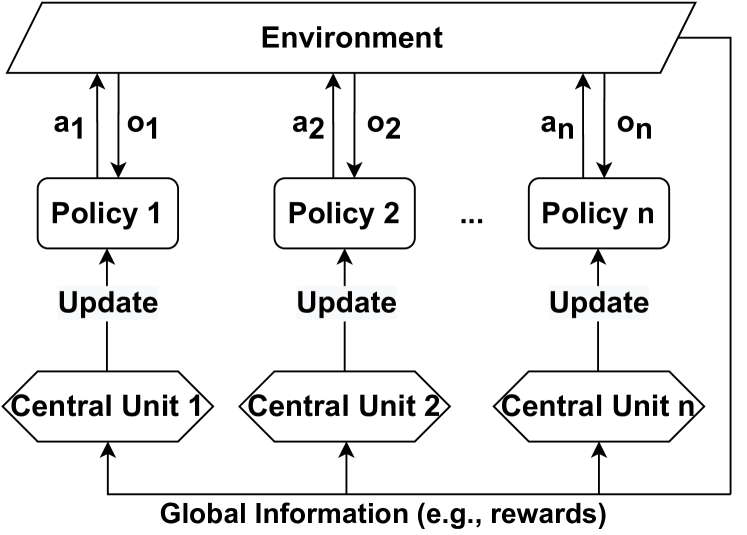
## Diagram: Multi-Agent Reinforcement Learning Architecture
### Overview
The image is a technical diagram illustrating a multi-agent reinforcement learning (MARL) system architecture. It depicts a centralized training with decentralized execution framework where multiple independent policies interact with a shared environment, and their updates are coordinated by separate central units using global information.
### Components/Axes
The diagram is structured into three main horizontal layers, with vertical columns representing individual agents.
**1. Top Layer (Environment):**
* **Component:** A single parallelogram spanning the top of the diagram.
* **Label:** `Environment`
* **Function:** Represents the external world or simulation with which all agents interact.
**2. Middle Layer (Agents/Policies):**
* **Components:** Three rectangular boxes arranged horizontally, representing a scalable number of agents.
* **Labels (from left to right):** `Policy 1`, `Policy 2`, `Policy n`
* **Ellipsis:** The notation `...` between `Policy 2` and `Policy n` indicates a sequence, implying there are multiple policies (from 1 to n).
* **Interactions with Environment:**
* Each Policy box has a pair of vertical arrows connecting it to the Environment above.
* **Upward Arrow (Action):** Labeled `a1`, `a2`, `an` respectively. Represents the action output from the policy to the environment.
* **Downward Arrow (Observation):** Labeled `o1`, `o2`, `on` respectively. Represents the observation or state input from the environment to the policy.
**3. Bottom Layer (Central Units & Global Information):**
* **Components:** Three hexagonal boxes arranged horizontally, each directly below a corresponding Policy box.
* **Labels (from left to right):** `Central Unit 1`, `Central Unit 2`, `Central Unit n`
* **Update Mechanism:** Each Central Unit has an upward-pointing arrow labeled `Update` directed at its corresponding Policy box above. This indicates the central unit is responsible for updating the parameters of its assigned policy.
* **Global Information Source:** A text label at the very bottom of the diagram.
* **Label:** `Global Information (e.g., rewards)`
* **Flow:** Three upward-pointing arrows originate from this label, one pointing to the base of each Central Unit. This shows that global information (such as shared rewards or system-wide state) is fed into each central unit to inform the policy updates.
### Detailed Analysis
**Spatial Layout & Flow:**
* The diagram is organized in a top-down flow: Environment → Policies → Central Units.
* The primary data flow is vertical within each column (e.g., Environment ↔ Policy 1 ↔ Central Unit 1).
* A secondary, horizontal flow of "Global Information" feeds into all Central Units from the bottom, creating a many-to-one relationship from global data to the decentralized update units.
**Component Relationships:**
* **Policy-Environment Loop:** Each `Policy i` engages in a direct, independent interaction loop with the `Environment`, sending actions (`ai`) and receiving observations (`oi`).
* **Centralized Update:** Each `Policy i` is not updated by its own interaction data alone. Instead, its update is mediated by a dedicated `Central Unit i`.
* **Global Coordination:** The `Central Units` do not operate in isolation. They all receive the same `Global Information`, which likely includes aggregated rewards or global state information. This allows for coordinated learning across all agents, even though their execution (the Policy-Environment interaction) is decentralized.
### Key Observations
1. **Scalability:** The use of `n` and the ellipsis (`...`) explicitly denotes that this architecture is designed for a variable and potentially large number of agents (`n`).
2. **Separation of Concerns:** The diagram cleanly separates the *execution* component (Policy) from the *learning/update* component (Central Unit) for each agent.
3. **Hybrid Information Flow:** The system combines local, agent-specific information (the `ai`/`oi` loop) with global, shared information (the `Global Information` feed) for the learning process.
4. **Symmetry:** The structure is perfectly symmetric across all `n` columns, indicating a homogeneous agent architecture where each agent follows the same interaction and update protocol.
### Interpretation
This diagram represents a specific paradigm in multi-agent reinforcement learning, often referred to as **Centralized Training with Decentralized Execution (CTDE)**.
* **What it demonstrates:** The architecture enables agents to learn cooperative or competitive behaviors by leveraging global information during training (via the Central Units), while allowing them to act independently based on their local observations during deployment (the Policy-Environment loop).
* **Relationship between elements:** The `Environment` is the shared testing ground. The `Policies` are the individual agents' brains. The `Central Units` are the trainers or critics that improve each agent's brain using both the agent's own experiences and a global perspective (`Global Information`). The `Update` arrow is the critical learning signal.
* **Purpose and Implications:** This design aims to solve the non-stationarity problem in MARL (where one agent's learning changes the environment for others) by providing a stable, global learning signal. It suggests a system where individual agents can be deployed efficiently (decentralized execution) but are trained intelligently with system-wide awareness (centralized training). The "e.g., rewards" note implies that the global information is likely used to shape a shared or team-based objective function.