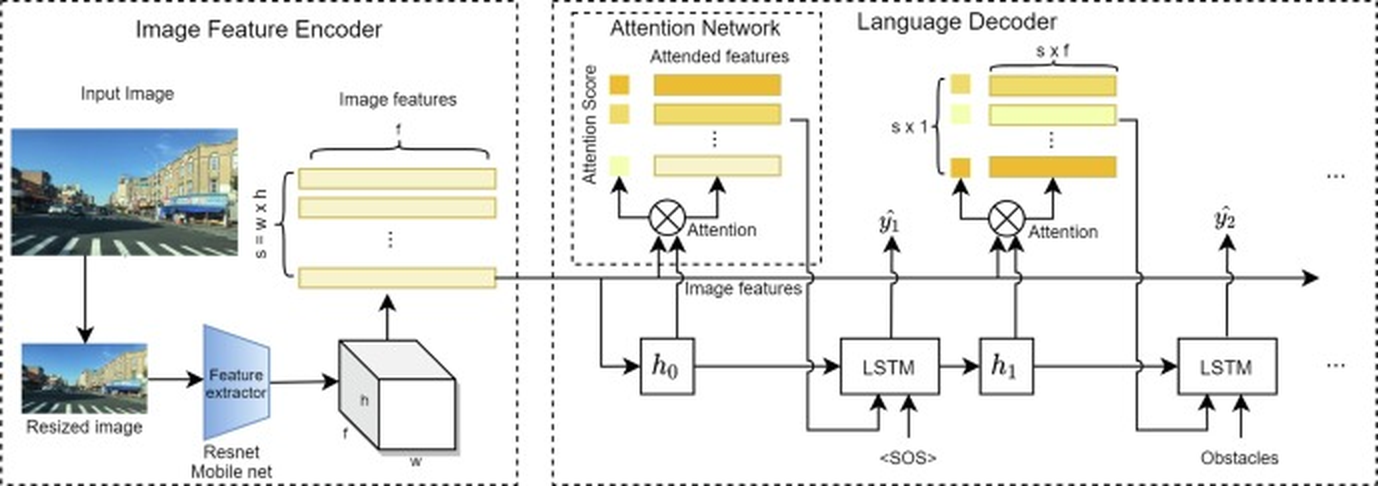
## Diagram: Image Captioning Architecture
### Overview
The image presents a diagram of an image captioning architecture, which consists of three main components: an Image Feature Encoder, an Attention Network, and a Language Decoder. The diagram illustrates the flow of information between these components, starting from an input image and ending with a generated sequence of words (caption).
### Components/Axes
* **Image Feature Encoder:** This module processes the input image to extract relevant features. It includes:
* **Input Image:** A photograph of a street scene.
* **Resized Image:** A smaller version of the input image.
* **Feature extractor:** A Resnet Mobile net, which extracts features from the resized image.
* **Image features:** A set of feature maps with dimensions s = w x h, where s is the number of features, w is the width, and h is the height.
* **Attention Network:** This module focuses on the most relevant image features for generating the caption. It includes:
* **Attention Score:** A measure of the importance of each image feature.
* **Attended features:** The image features that are most relevant to the current word being generated. The attended features are represented as a stack of horizontal bars, with the top bars being lighter in color and the bottom bars being darker, suggesting a higher attention score.
* **Language Decoder:** This module generates the caption based on the attended image features. It includes:
* **LSTM:** A Long Short-Term Memory network, which is a type of recurrent neural network.
* **<SOS>:** Start of Sequence token.
* **Obstacles:** Represents the input of obstacles.
* **ŷ1, ŷ2:** Predicted words in the caption.
* The output of the LSTM is fed into an attention mechanism, which combines the image features with the hidden state of the LSTM to predict the next word in the caption. The output is a sequence of words with dimensions s x 1, where s is the sequence length.
### Detailed Analysis
1. **Image Feature Encoder:**
* The input image is first resized and then passed through a feature extractor (Resnet Mobile net).
* The feature extractor outputs a set of feature maps with dimensions s = w x h.
2. **Attention Network:**
* The image features are fed into an attention network, which calculates an attention score for each feature.
* The attended features are then passed to the language decoder.
3. **Language Decoder:**
* The attended features are fed into an LSTM network, which generates the caption.
* The LSTM network is initialized with a start-of-sequence token (<SOS>).
* The output of the LSTM is fed into an attention mechanism, which combines the image features with the hidden state of the LSTM to predict the next word in the caption.
* The process is repeated until the end-of-sequence token is generated.
### Key Observations
* The architecture uses an attention mechanism to focus on the most relevant image features for generating the caption.
* The language decoder uses an LSTM network to generate the caption.
* The architecture is end-to-end trainable, meaning that all of the components can be trained together.
### Interpretation
The diagram illustrates a common architecture for image captioning, which combines a convolutional neural network (CNN) for image feature extraction with a recurrent neural network (RNN) for language generation. The attention mechanism allows the model to focus on the most relevant parts of the image when generating each word in the caption. This architecture has been shown to be effective for generating accurate and descriptive captions for images. The flow of information is from the image, through feature extraction, attention weighting, and finally, language decoding to produce a textual description.