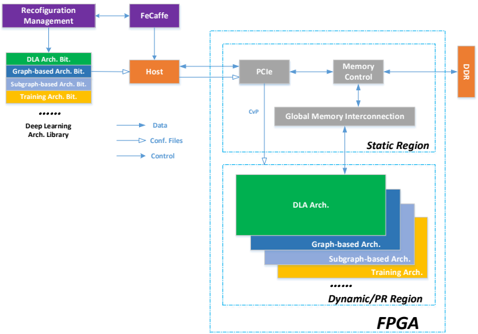
## Diagram: FPGA-Based Deep Learning Architecture
### Overview
The image depicts a high-level block diagram of an FPGA-based deep learning architecture. It illustrates the flow of data and control signals between various components, including a host processor, PCIe interface, memory control, and the FPGA itself, which is partitioned into static and dynamic/programmable regions. The diagram highlights the use of different deep learning architectures (DLA, Graph-based, Subgraph-based, Training) that can be dynamically loaded onto the FPGA.
### Components/Axes
The diagram consists of the following key components:
* **Reconfiguration Management:** Top-left corner.
* **FeCaffe:** Connected to Reconfiguration Management.
* **Host:** Central component, receiving data and control signals.
* **Deep Learning Arch. Library:** Left side, containing DLA Arch. Bit, Graph-based Arch. Bit, Subgraph-based Arch. Bit, Training Arch. Bit, and ellipsis indicating more architectures.
* **PCIe:** Within the "Static Region" block.
* **Memory Control:** Within the "Static Region" block.
* **Global Memory Interconnection:** Connects PCIe and Memory Control to the Dynamic/PR Region.
* **Static Region:** A large rectangular block encompassing PCIe, Memory Control, and Global Memory Interconnection.
* **Dynamic/PR Region:** Bottom portion of the FPGA, containing stacked blocks representing different architectures: DLA Arch., Graph-based Arch., Subgraph-based Arch., Training Arch., and ellipsis indicating more architectures.
* **FPGA:** Bottom-right corner, encompassing the Static and Dynamic/PR Regions.
* **DDR:** Right side, connected to Memory Control.
Data flow is indicated by solid arrows, configuration files by dashed arrows, and control signals by dashed-dotted arrows.
### Detailed Analysis or Content Details
The diagram shows the following data and control flow:
1. **Reconfiguration Management** sends signals to **FeCaffe**.
2. **FeCaffe** sends signals to the **Host**.
3. **Deep Learning Arch. Library** sends **Data** to the **Host**.
4. **Deep Learning Arch. Library** sends **Conf. Files** to the **Host**.
5. **Deep Learning Arch. Library** sends **Control** signals to the **Host**.
6. **Host** sends signals to **PCIe** and **Memory Control** within the **Static Region**.
7. **PCIe** and **Memory Control** are connected via **Global Memory Interconnection** to the **Dynamic/PR Region**.
8. **Memory Control** is connected to **DDR**.
9. The **Dynamic/PR Region** contains stacked blocks representing different deep learning architectures:
* **DLA Arch.** (Green) - Topmost layer.
* **Graph-based Arch.** (Blue) - Second layer.
* **Subgraph-based Arch.** (Orange) - Third layer.
* **Training Arch.** (Yellow) - Bottom layer.
* Ellipsis indicates additional architectures.
The diagram does not provide specific numerical values or quantitative data. It is a conceptual representation of the system architecture.
### Key Observations
* The FPGA is partitioned into a static region and a dynamic/programmable region. This allows for flexibility in deploying different deep learning architectures.
* The Deep Learning Arch. Library provides a repository of pre-designed architectures that can be loaded onto the FPGA.
* The Host processor acts as the central control point, managing data flow and configuration.
* The use of PCIe and Memory Control suggests a high-bandwidth interface to external memory (DDR).
* The diagram emphasizes the reconfigurability of the FPGA, enabling it to adapt to different deep learning tasks.
### Interpretation
This diagram illustrates a flexible and reconfigurable FPGA-based system for accelerating deep learning workloads. The separation of the FPGA into static and dynamic regions allows for a balance between performance and adaptability. The static region likely handles core functionalities like PCIe communication and memory control, while the dynamic region hosts the deep learning architectures themselves. The ability to load different architectures from the Deep Learning Arch. Library enables the system to be optimized for various tasks, such as inference, training, or specialized graph processing. The FeCaffe component suggests the use of a specific deep learning framework. The overall architecture aims to leverage the parallel processing capabilities of FPGAs to achieve high performance and energy efficiency in deep learning applications. The diagram is a conceptual overview and does not provide details on the specific implementation of the architectures or the communication protocols used.