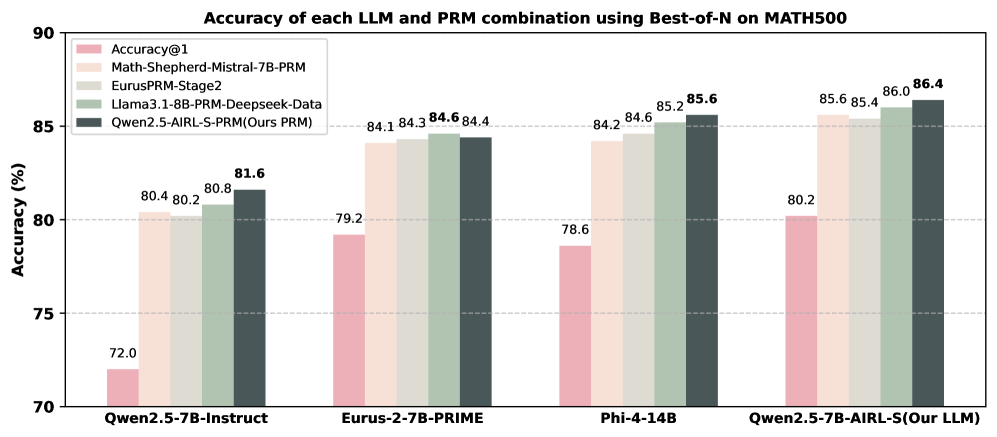
## Bar Chart: Accuracy of LLM and PRM Combinations
### Overview
The image is a bar chart comparing the accuracy of different Large Language Model (LLM) and PRM (presumably a type of prompting or reasoning method) combinations on the MATH500 dataset, using a "Best-of-N" approach. The chart displays the accuracy percentages for each combination, with different colored bars representing different configurations.
### Components/Axes
* **Title:** Accuracy of each LLM and PRM combination using Best-of-N on MATH500
* **Y-axis:** Accuracy (%)
* Scale: 70 to 90, with gridlines at 75, 80, and 85.
* **X-axis:** Categorical, representing different LLM and PRM combinations:
* Qwen2.5-7B-Instruct
* Eurus-2-7B-PRIME
* Phi-4-14B
* Qwen2.5-7B-AIRL-S(Our LLM)
* **Legend:** Located in the top-left corner.
* Accuracy@1 (Pink)
* Math-Shepherd-Mistral-7B-PRM (Light Pink/Beige)
* EurusPRM-Stage2 (Light Grey/Off-White)
* Llama3.1-8B-PRM-Deepseek-Data (Green)
* Qwen2.5-AIRL-S-PRM(Ours PRM) (Dark Grey)
### Detailed Analysis
The chart presents accuracy data for four LLMs, each tested with five different PRM configurations. The accuracy values are displayed above each bar.
**Qwen2.5-7B-Instruct**
* Accuracy@1 (Pink): 72.0
* Math-Shepherd-Mistral-7B-PRM (Light Pink/Beige): 80.4
* EurusPRM-Stage2 (Light Grey/Off-White): 80.2
* Llama3.1-8B-PRM-Deepseek-Data (Green): 80.8
* Qwen2.5-AIRL-S-PRM(Ours PRM) (Dark Grey): 81.6
**Eurus-2-7B-PRIME**
* Accuracy@1 (Pink): 79.2
* Math-Shepherd-Mistral-7B-PRM (Light Pink/Beige): 84.1
* EurusPRM-Stage2 (Light Grey/Off-White): 84.3
* Llama3.1-8B-PRM-Deepseek-Data (Green): 84.6
* Qwen2.5-AIRL-S-PRM(Ours PRM) (Dark Grey): 84.4
**Phi-4-14B**
* Accuracy@1 (Pink): 78.6
* Math-Shepherd-Mistral-7B-PRM (Light Pink/Beige): 84.2
* EurusPRM-Stage2 (Light Grey/Off-White): 84.6
* Llama3.1-8B-PRM-Deepseek-Data (Green): 85.2
* Qwen2.5-AIRL-S-PRM(Ours PRM) (Dark Grey): 85.6
**Qwen2.5-7B-AIRL-S(Our LLM)**
* Accuracy@1 (Pink): 80.2
* Math-Shepherd-Mistral-7B-PRM (Light Pink/Beige): 85.6
* EurusPRM-Stage2 (Light Grey/Off-White): 85.4
* Llama3.1-8B-PRM-Deepseek-Data (Green): 86.0
* Qwen2.5-AIRL-S-PRM(Ours PRM) (Dark Grey): 86.4
### Key Observations
* The "Accuracy@1" configuration (pink bars) consistently shows the lowest accuracy for each LLM.
* The "Qwen2.5-AIRL-S-PRM(Ours PRM)" configuration (dark grey bars) generally achieves the highest accuracy for each LLM, or is very close to the highest.
* The LLM "Qwen2.5-7B-AIRL-S(Our LLM)" achieves the highest overall accuracy of 86.4% when combined with "Qwen2.5-AIRL-S-PRM(Ours PRM)".
* The LLM "Qwen2.5-7B-Instruct" has the lowest accuracy across all PRM combinations compared to the other LLMs.
### Interpretation
The data suggests that the choice of PRM significantly impacts the accuracy of LLMs on the MATH500 dataset. The "Qwen2.5-AIRL-S-PRM(Ours PRM)" configuration appears to be the most effective PRM across all tested LLMs. The "Accuracy@1" configuration, likely representing a baseline or simpler prompting method, consistently underperforms compared to the other PRMs. The LLM "Qwen2.5-7B-AIRL-S(Our LLM)" combined with "Qwen2.5-AIRL-S-PRM(Ours PRM)" demonstrates the best performance overall, indicating a potentially synergistic effect between this specific LLM and PRM combination. The relatively lower performance of "Qwen2.5-7B-Instruct" suggests that its architecture or training might be less suited for the MATH500 task compared to the other LLMs.