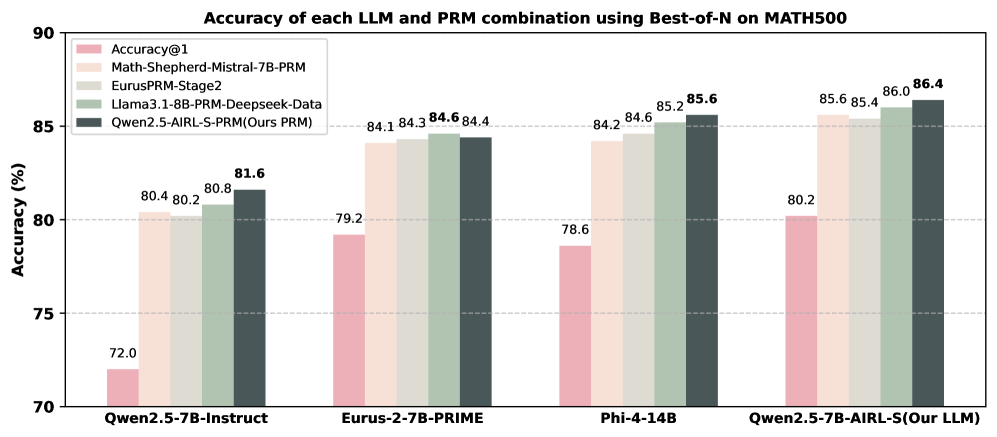
## Bar Chart: Accuracy of LLM and PRM Combinations on MATH500
### Overview
This bar chart displays the accuracy of different Large Language Models (LLMs) combined with different Program-aided Reasoning Models (PRMs) on the MATH500 dataset, using a Best-of-N evaluation method. The accuracy is measured as Accuracy@1, representing the percentage of correct answers on the first attempt. The chart compares four different LLM/PRM combinations.
### Components/Axes
* **Title:** "Accuracy of each LLM and PRM combination using Best-of-N on MATH500" (Top-center)
* **X-axis:** LLM/PRM Combinations: "Qwen2.5-7B-Instruct", "Eurus-2-7B-PRIME", "Phi-4-14B", "Qwen2.5-7B-AIRL-S(Our LLM)" (Bottom-center)
* **Y-axis:** Accuracy (%) - Scale ranges from 70 to 90, with increments of 5. (Left-side)
* **Legend:** Located in the top-left corner, identifying the color-coded data series:
* Accuracy@1 (Pink)
* Math-Shepherd-Mistral-7B-PRM (Green)
* EurusPRM-Stage2 (Gray)
* Llama3.1-8B-PRM-Deepseek-Data (Light Gray)
* Qwen2.5-AIRL-S-PRM(Ours PRM) (Dark Green)
### Detailed Analysis
The chart consists of four groups of bars, one for each LLM/PRM combination. Each group contains four bars, representing the accuracy of each PRM when paired with the corresponding LLM.
* **Qwen2.5-7B-Instruct:**
* Accuracy@1: Approximately 72.0%
* Math-Shepherd-Mistral-7B-PRM: Approximately 80.4%
* EurusPRM-Stage2: Approximately 80.2%
* Llama3.1-8B-PRM-Deepseek-Data: Approximately 81.6%
* Qwen2.5-AIRL-S-PRM(Ours PRM): Approximately 80.8%
* **Eurus-2-7B-PRIME:**
* Accuracy@1: Approximately 79.2%
* Math-Shepherd-Mistral-7B-PRM: Approximately 84.1%
* EurusPRM-Stage2: Approximately 84.3%
* Llama3.1-8B-PRM-Deepseek-Data: Approximately 84.6%
* Qwen2.5-AIRL-S-PRM(Ours PRM): Approximately 84.4%
* **Phi-4-14B:**
* Accuracy@1: Approximately 78.6%
* Math-Shepherd-Mistral-7B-PRM: Approximately 84.2%
* EurusPRM-Stage2: Approximately 84.6%
* Llama3.1-8B-PRM-Deepseek-Data: Approximately 85.6%
* Qwen2.5-AIRL-S-PRM(Ours PRM): Approximately 85.2%
* **Qwen2.5-7B-AIRL-S(Our LLM):**
* Accuracy@1: Approximately 80.2%
* Math-Shepherd-Mistral-7B-PRM: Approximately 85.6%
* EurusPRM-Stage2: Approximately 85.4%
* Llama3.1-8B-PRM-Deepseek-Data: Approximately 86.0%
* Qwen2.5-AIRL-S-PRM(Ours PRM): Approximately 86.4%
### Key Observations
* The "Qwen2.5-7B-AIRL-S(Our LLM)" combination consistently achieves the highest accuracy across all PRMs.
* "Accuracy@1" consistently shows the lowest accuracy compared to the other PRMs for each LLM.
* The "Llama3.1-8B-PRM-Deepseek-Data" and "Qwen2.5-AIRL-S-PRM(Ours PRM)" PRMs generally perform better than "Math-Shepherd-Mistral-7B-PRM" and "EurusPRM-Stage2".
* The accuracy scores are relatively close for most combinations, suggesting that the choice of PRM has a significant impact, but the LLM also plays a role.
### Interpretation
The data suggests that combining LLMs with PRMs significantly improves performance on the MATH500 dataset compared to using the LLMs alone (as indicated by the lower "Accuracy@1" scores). The "Qwen2.5-7B-AIRL-S" LLM, when paired with various PRMs, consistently demonstrates the highest accuracy, indicating its superior capability in this task. The "Llama3.1-8B-PRM-Deepseek-Data" and "Qwen2.5-AIRL-S-PRM(Ours PRM)" PRMs appear to be particularly effective in enhancing the reasoning abilities of the LLMs. The relatively small differences in accuracy between the PRMs suggest that the optimal PRM choice may depend on the specific LLM being used. The consistent trend of higher accuracy with PRM integration highlights the benefit of program-aided reasoning for complex mathematical problem-solving. The data points to a synergistic relationship between LLMs and PRMs, where each component complements the other to achieve better results.