TECHNICAL ASSET FINGERPRINT
22d7ec84e8ae462ec5115695
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
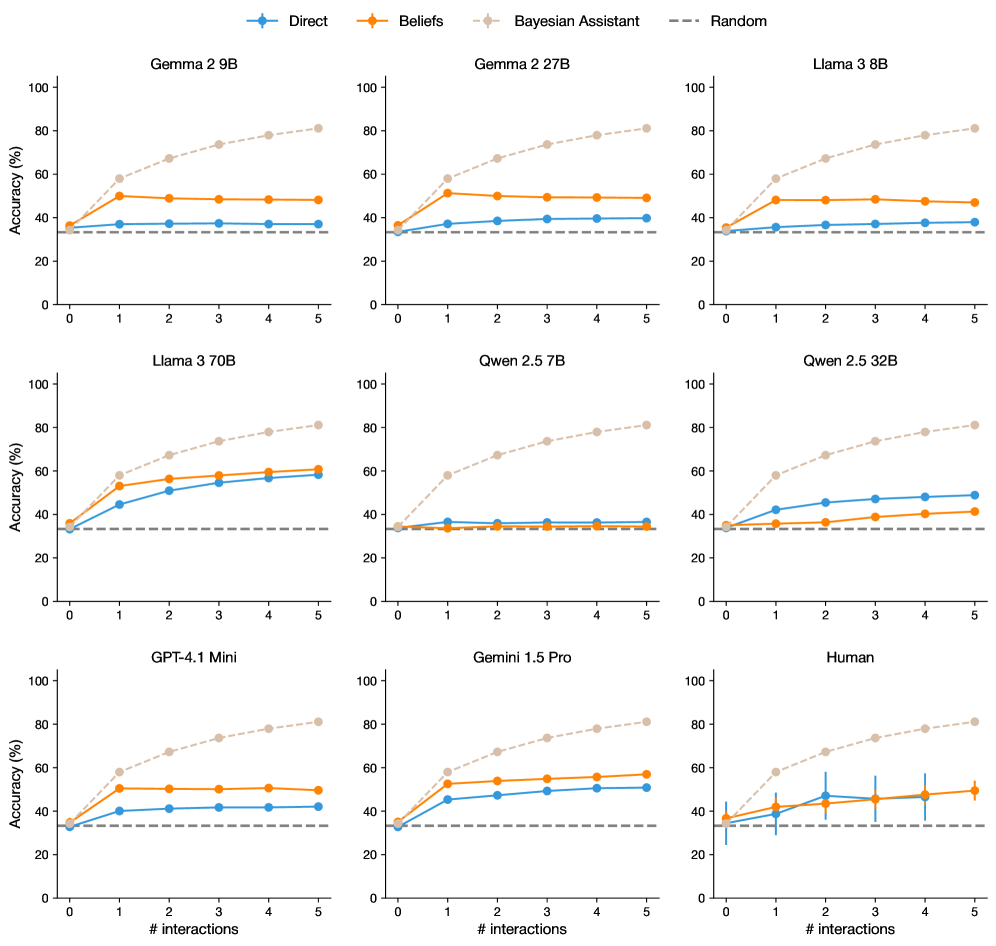
## Multi-Panel Line Chart: Accuracy of Different Methods Across AI Models and Humans
### Overview
The image displays a 3x3 grid of nine line charts. Each chart compares the performance of four different methods ("Direct", "Beliefs", "Bayesian Assistant", "Random") on a specific AI model or human participants. The performance metric is "Accuracy (%)" plotted against the number of interactions (0 to 5). The overall purpose is to demonstrate how different prompting or reasoning strategies affect accuracy as an agent (AI or human) gains more interaction experience with a task.
### Components/Axes
* **Global Legend:** Positioned at the top center of the entire figure.
* `Direct`: Blue line with diamond markers.
* `Beliefs`: Orange line with diamond markers.
* `Bayesian Assistant`: Beige/light brown dashed line with diamond markers.
* `Random`: Gray dashed horizontal line (baseline).
* **Subplot Titles:** Each of the nine charts has a centered title indicating the subject:
* Row 1: `Gemma 2 9B`, `Gemma 2 27B`, `Llama 3 8B`
* Row 2: `Llama 3 70B`, `Qwen 2.5 7B`, `Qwen 2.5 32B`
* Row 3: `GPT-4.1 Mini`, `Gemini 1.5 Pro`, `Human`
* **Axes (Consistent across all subplots):**
* **X-axis:** Label: `# interactions`. Scale: Linear, from 0 to 5 with integer markers.
* **Y-axis:** Label: `Accuracy (%)`. Scale: Linear, from 0 to 100 with increments of 20.
* **Data Series:** Each chart contains four lines corresponding to the global legend. The "Random" baseline is a flat, dashed gray line at approximately 33.3% accuracy across all charts.
### Detailed Analysis
**Row 1: Gemma 2 9B, Gemma 2 27B, Llama 3 8B**
* **Trend:** In all three charts, the "Bayesian Assistant" (beige) shows a strong, near-linear upward trend, starting near the baseline at interaction 0 and reaching ~80% accuracy by interaction 5. The "Beliefs" (orange) method shows a sharp initial increase from interaction 0 to 1 (to ~50%), then plateaus. The "Direct" (blue) method shows a very slight, gradual increase, remaining below 40%. "Random" (gray) is constant at ~33%.
* **Approximate Values (Gemma 2 9B):**
* Bayesian Assistant: 0: ~35%, 1: ~58%, 2: ~67%, 3: ~73%, 4: ~78%, 5: ~81%
* Beliefs: 0: ~35%, 1: ~50%, 2: ~49%, 3: ~48%, 4: ~48%, 5: ~48%
* Direct: 0: ~35%, 1: ~37%, 2: ~37%, 3: ~37%, 4: ~37%, 5: ~37%
* **Note:** The patterns for Gemma 2 27B and Llama 3 8B are visually almost identical to Gemma 2 9B.
**Row 2: Llama 3 70B, Qwen 2.5 7B, Qwen 2.5 32B**
* **Llama 3 70B:** Shows a different pattern. "Bayesian Assistant" still leads with a strong upward trend (~80% at 5). However, both "Direct" and "Beliefs" show significant, parallel improvement, rising from ~35% to nearly 60% by interaction 5. "Direct" and "Beliefs" are very close in performance.
* **Qwen 2.5 7B:** "Bayesian Assistant" follows the standard strong upward trend. "Direct" and "Beliefs" are nearly flat and overlapping, hovering just above the "Random" baseline (~35-36%) across all interactions.
* **Qwen 2.5 32B:** "Bayesian Assistant" trend is standard. Here, "Direct" (blue) shows a clear upward trend, reaching ~48% by interaction 5. "Beliefs" (orange) also increases but more slowly, reaching ~40% at interaction 5. "Direct" outperforms "Beliefs" for this model.
**Row 3: GPT-4.1 Mini, Gemini 1.5 Pro, Human**
* **GPT-4.1 Mini:** Resembles the Row 1 pattern. "Bayesian Assistant" leads strongly. "Beliefs" plateaus around 50% after interaction 1. "Direct" shows a slight increase to ~42%.
* **Gemini 1.5 Pro:** "Bayesian Assistant" leads. Both "Direct" and "Beliefs" show steady, parallel improvement, with "Beliefs" maintaining a slight lead over "Direct" (ending at ~57% vs. ~51% at interaction 5).
* **Human:** This chart includes vertical error bars on the "Direct" and "Beliefs" data points, indicating variability in human performance. "Bayesian Assistant" shows the standard strong trend. "Direct" and "Beliefs" are intertwined, both showing a gradual increase with significant overlap in their error bars, ending near 50% at interaction 5. The "Random" baseline is at ~33%.
### Key Observations
1. **Dominant Method:** The "Bayesian Assistant" method consistently and significantly outperforms all other methods across every single model and human subjects. Its accuracy improves reliably with more interactions.
2. **Model-Specific Behavior:** The relative performance of "Direct" vs. "Beliefs" is highly model-dependent. In some models (Gemma series, Llama 3 8B, GPT-4.1 Mini), "Beliefs" is clearly superior. In others (Llama 3 70B, Gemini 1.5 Pro), they are comparable. In Qwen 2.5 32B, "Direct" is better, and in Qwen 2.5 7B, both are ineffective.
3. **Human Performance:** Human accuracy with "Direct" or "Beliefs" methods shows high variability (large error bars) and does not clearly surpass the AI models, ending in a similar range (~50%).
4. **Baseline:** The "Random" baseline is consistently at ~33.3%, suggesting a 3-choice task.
5. **Plateau Effect:** For many models (e.g., Gemma series), the "Beliefs" method shows a rapid initial gain but then plateaus, while "Bayesian Assistant" continues to improve.
### Interpretation
This data strongly suggests that incorporating a structured Bayesian reasoning framework ("Bayesian Assistant") provides a substantial and robust advantage in learning from interactions compared to simpler "Direct" prompting or "Beliefs"-based approaches. The advantage is universal across a diverse set of state-of-the-art AI models and even holds for humans.
The variability in the "Direct" vs. "Beliefs" comparison indicates that the benefit of explicitly modeling beliefs is not universal and may depend on the underlying capabilities or training of the specific model. Models like Qwen 2.5 7B appear to lack the capacity to utilize either interactive strategy effectively beyond random guessing.
The human data is particularly insightful. It shows that unaided human reasoning ("Direct" or "Beliefs") in this interactive setting is noisy and does not consistently outperform AI models, highlighting the potential for AI systems with appropriate reasoning frameworks (like the Bayesian Assistant) to surpass human performance in iterative learning tasks. The chart collectively argues for the importance of methodological design (the reasoning framework) over raw model size or human intuition for this class of problem.
DECODING INTELLIGENCE...