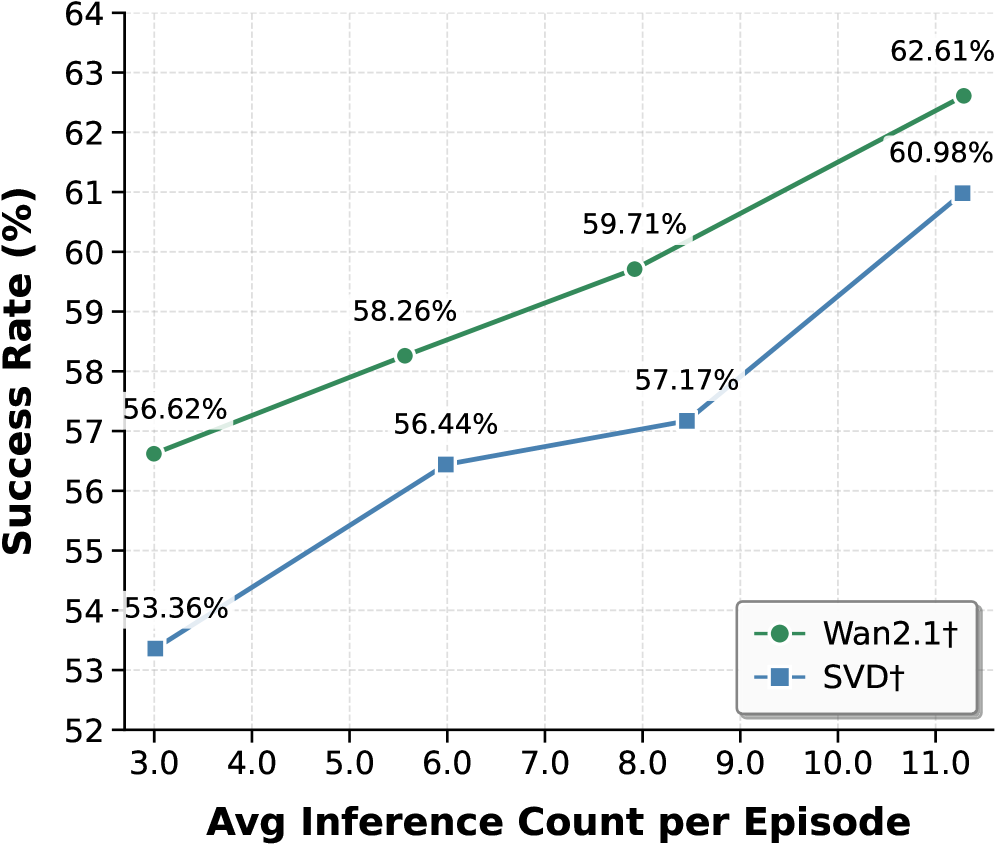
## Line Graph: Algorithm Performance Comparison (Success Rate vs. Inference Count)
### Overview
The image is a line graph comparing the success rates of two algorithms, **Wan2.1†** (green line with circles) and **SVD†** (blue line with squares), across varying average inference counts per episode. The graph spans inference counts from 3.0 to 11.0 episodes, with success rates ranging from 52% to 64%.
---
### Components/Axes
- **X-axis**: "Avg Inference Count per Episode" (3.0 to 11.0, increments of 1.0).
- **Y-axis**: "Success Rate (%)" (52% to 64%, increments of 1%).
- **Legend**: Located in the bottom-right corner, mapping:
- Green line with circles → **Wan2.1†**
- Blue line with squares → **SVD†**
---
### Detailed Analysis
#### Wan2.1† (Green Line)
- **Data Points**:
- (3.0, 56.62%)
- (5.5, 58.26%)
- (8.0, 59.71%)
- (11.0, 62.61%)
- **Trend**: Steadily upward slope, with consistent gains in success rate as inference count increases.
#### SVD† (Blue Line)
- **Data Points**:
- (3.0, 53.36%)
- (6.0, 56.44%)
- (8.0, 57.17%)
- (11.0, 60.98%)
- **Trend**: Gradual upward slope, but with slower growth compared to Wan2.1†.
---
### Key Observations
1. **Performance Gap**: Wan2.1† consistently outperforms SVD† across all inference counts.
- At 3.0 episodes: Wan2.1† (56.62%) vs. SVD† (53.36%) → **+3.26% advantage**.
- At 11.0 episodes: Wan2.1† (62.61%) vs. SVD† (60.98%) → **+1.63% advantage**.
2. **Efficiency**: Wan2.1† achieves higher success rates with fewer inference counts (e.g., 59.71% at 8.0 episodes vs. SVD†'s 57.17%).
3. **Scalability**: Both algorithms improve with more inference counts, but Wan2.1† scales more effectively.
---
### Interpretation
The data suggests **Wan2.1† is a more efficient and effective algorithm** for the task measured, likely due to superior optimization or architecture. The steeper slope of Wan2.1† indicates it leverages inference counts more effectively to improve success rates. SVD†, while still improving, lags behind, highlighting potential limitations in its design or training. This trend could inform algorithm selection in resource-constrained environments where inference efficiency is critical.