## Heatmap Comparison: Model Layer Vulnerability Analysis
### Overview
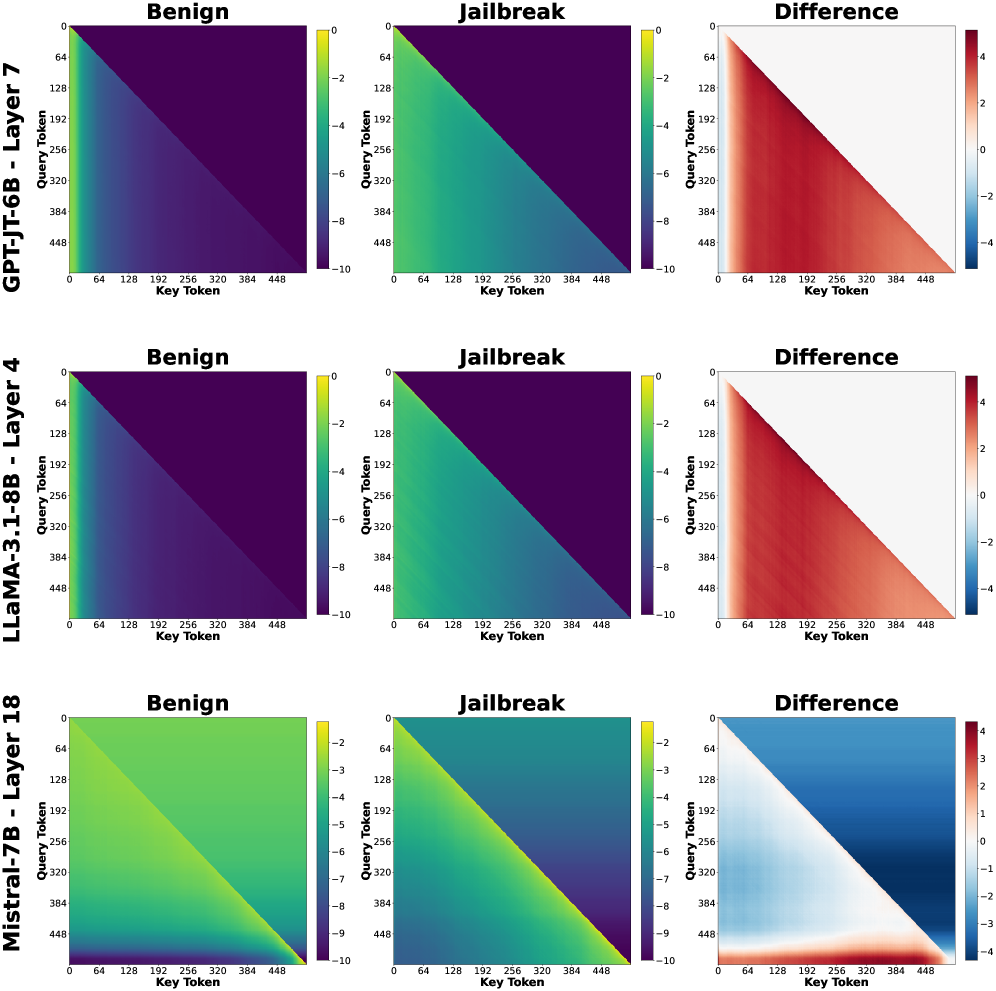
The image presents a comparative analysis of three language models (GPT-J-T6B, LLaMA-3.1-8B, Mistral-7B) across different layers (7, 4, 18) using three heatmaps per model: Benign, Jailbreak, and Difference. Each heatmap visualizes token interaction patterns through color gradients, with spatial grounding of elements following a consistent layout.
### Components/Axes
1. **Models/Layers**:
- Top row: GPT-J-T6B - Layer 7
- Middle row: LLaMA-3.1-8B - Layer 4
- Bottom row: Mistral-7B - Layer 18
2. **Axes**:
- X-axis: Key Token (0-448 range)
- Y-axis: Query Token (0-448 range)
- Color scales:
- Benign/Jailbreak: -10 (dark purple) to 0 (yellow)
- Difference: -4 (blue) to 4 (red)
3. **Legend Placement**:
- Right-aligned color bars with numerical ranges
- Spatial consistency across all panels
### Detailed Analysis
1. **GPT-J-T6B - Layer 7**:
- Benign: Dark purple gradient (values -10 to -6)
- Jailbreak: Green gradient (values -8 to -2)
- Difference: Red gradient (values 2-4)
- Key tokens: 64-448 show strongest differences
2. **LLaMA-3.1-8B - Layer 4**:
- Benign: Purple gradient (-10 to -4)
- Jailbreak: Teal gradient (-8 to -4)
- Difference: Mixed red/blue (values -3 to 3)
- Notable: 192-384 key tokens show highest variability
3. **Mistral-7B - Layer 18**:
- Benign: Light green gradient (-5 to -1)
- Jailbreak: Dark green gradient (-9 to -5)
- Difference: Blue gradient (-4 to 0)
- Key observation: Uniform negative differences across all tokens
### Key Observations
1. **Vulnerability Patterns**:
- GPT-J-T6B Layer 7 shows highest jailbreak susceptibility (red difference gradient)
- Mistral-7B Layer 18 demonstrates strongest resistance (blue difference gradient)
- LLaMA-3.1-8B Layer 4 exhibits mixed vulnerability (bipolar difference values)
2. **Token Interaction**:
- All models show diagonal patterns in Benign/Jailbreak heatmaps
- Difference heatmaps reveal model-specific interaction shifts:
- GPT-J: Consistent positive differences (security vulnerability)
- LLaMA: Mixed positive/negative differences (context-dependent vulnerability)
- Mistral: Consistent negative differences (resilience)
### Interpretation
The data suggests significant architectural differences in how these models handle adversarial inputs:
1. **GPT-J-T6B Layer 7** appears most vulnerable to jailbreaking, with consistent positive differences indicating predictable token manipulation patterns.
2. **Mistral-7B Layer 18** shows architectural robustness, with uniform negative differences suggesting effective token interaction safeguards.
3. **LLaMA-3.1-8B Layer 4** demonstrates context-dependent vulnerabilities, with mixed difference values indicating potential for both exploitation and mitigation through input framing.
The consistent diagonal patterns across Benign/Jailbreak heatmaps suggest shared architectural constraints in token processing, while the Difference heatmaps reveal critical layer-specific security characteristics. These findings highlight the importance of layer-specific security considerations in model deployment.