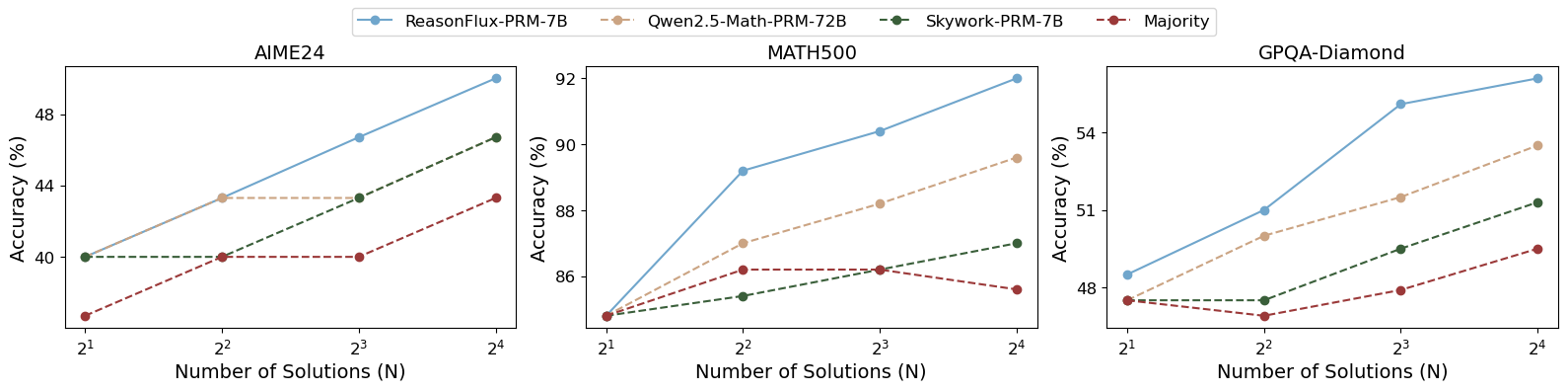
## Line Graphs: AI Model Accuracy Across Datasets
### Overview
The image contains three line graphs comparing the accuracy of four AI models (ReasonFlux-PRM-7B, Gwen2.5-Math-PRM-7B, Skywork-PRM-7B, and Majority) across three datasets (AIME24, MATH500, GPQA-Diamond). Accuracy (%) is plotted against the number of solutions (N = 2¹ to 2⁴). Each graph shows distinct performance trends, with ReasonFlux-PRM-7B consistently outperforming other models.
---
### Components/Axes
- **X-axis**: "Number of Solutions (N)" with values 2¹, 2², 2³, 2⁴.
- **Y-axis**: "Accuracy (%)" ranging from ~35% to ~92% depending on the dataset.
- **Legend**:
- Blue: ReasonFlux-PRM-7B
- Orange: Gwen2.5-Math-PRM-7B
- Green: Skywork-PRM-7B
- Red: Majority
- **Datasets**:
- AIME24 (left graph)
- MATH500 (center graph)
- GPQA-Diamond (right graph)
---
### Detailed Analysis
#### AIME24 Dataset
- **ReasonFlux-PRM-7B (Blue)**: Starts at ~40% (2¹), increases steadily to ~49% (2⁴). Steepest slope.
- **Gwen2.5-Math-PRM-7B (Orange)**: Flat line at ~44% across all N values.
- **Skywork-PRM-7B (Green)**: Starts at ~40%, rises to ~47% (2⁴). Moderate slope.
- **Majority (Red)**: Starts at ~35%, increases to ~43% (2⁴). Gradual upward trend.
#### MATH500 Dataset
- **ReasonFlux-PRM-7B (Blue)**: Starts at ~85%, peaks at ~92% (2⁴). Strong upward trajectory.
- **Gwen2.5-Math-PRM-7B (Orange)**: Begins at ~85%, rises to ~89% (2⁴). Steady growth.
- **Skywork-PRM-7B (Green)**: Starts at ~85%, increases to ~88% (2⁴). Slight upward curve.
- **Majority (Red)**: Flat line at ~86% across all N values.
#### GPQA-Diamond Dataset
- **ReasonFlux-PRM-7B (Blue)**: Starts at ~48%, climbs to ~55% (2⁴). Consistent growth.
- **Gwen2.5-Math-PRM-7B (Orange)**: Begins at ~48%, rises to ~53% (2⁴). Moderate slope.
- **Skywork-PRM-7B (Green)**: Starts at ~48%, increases to ~51% (2⁴). Gradual rise.
- **Majority (Red)**: Starts at ~48%, peaks at ~49% (2⁴). Minimal improvement.
---
### Key Observations
1. **ReasonFlux-PRM-7B Dominance**: Outperforms all models in all datasets, with the steepest accuracy gains in AIME24 and MATH500.
2. **Majority Model Limitations**: Shows the lowest accuracy (35–49%) and minimal improvement across datasets.
3. **Dataset-Specific Performance**:
- **AIME24**: ReasonFlux gains ~9% accuracy (2¹→2⁴), while Gwen2.5 remains flat.
- **MATH500**: ReasonFlux achieves ~7% gain, Gwen2.5 ~4%.
- **GPQA-Diamond**: ReasonFlux gains ~7%, Gwen2.5 ~5%.
4. **Majority Model Stagnation**: No significant improvement in any dataset, suggesting it may represent a baseline or less adaptive approach.
---
### Interpretation
The data demonstrates that **ReasonFlux-PRM-7B** excels in reasoning tasks across diverse datasets, likely due to advanced problem-solving capabilities. Its performance scales effectively with increased solution complexity (N). In contrast, the **Majority model** underperforms, possibly reflecting a simpler or less optimized architecture. The **Gwen2.5-Math-PRM-7B** model shows dataset-specific strengths (e.g., flat performance in AIME24 but steady gains in MATH500), indicating potential specialization in mathematical reasoning. The **Skywork-PRM-7B** model bridges the gap between ReasonFlux and Majority, suggesting moderate adaptability. These trends highlight the importance of model architecture design for task-specific accuracy.