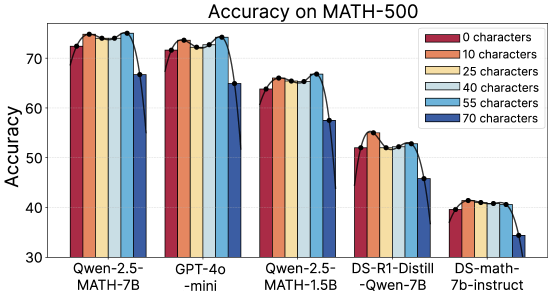
## Bar Chart: Accuracy on MATH-500
### Overview
The image is a bar chart comparing the accuracy of different language models on the MATH-500 dataset. The x-axis represents the language models, and the y-axis represents the accuracy, ranging from 30 to 75. Each model has a set of bars representing different input lengths (0 to 70 characters), indicated by color. A black line connects the tops of the bars for each model, showing the trend of accuracy as input length increases.
### Components/Axes
* **Title:** Accuracy on MATH-500
* **Y-axis:** Accuracy, with tick marks at 30, 40, 50, 60, and 70.
* **X-axis:** Language models:
* Qwen-2.5-MATH-7B
* GPT-4o-mini
* Qwen-2.5-MATH-1.5B
* DS-R1-Distill-Qwen-7B
* DS-math-7b-instruct
* **Legend:** Located at the top-right of the chart.
* Red: 0 characters
* Orange: 10 characters
* Yellow: 25 characters
* Light Blue: 40 characters
* Blue: 55 characters
* Dark Blue: 70 characters
### Detailed Analysis
Here's a breakdown of the accuracy for each model at different input lengths:
* **Qwen-2.5-MATH-7B:**
* 0 characters (Red): ~73
* 10 characters (Orange): ~74
* 25 characters (Yellow): ~75
* 40 characters (Light Blue): ~75
* 55 characters (Blue): ~74
* 70 characters (Dark Blue): ~65
* Trend: Accuracy is high and relatively stable for 0-55 characters, then drops for 70 characters.
* **GPT-4o-mini:**
* 0 characters (Red): ~72
* 10 characters (Orange): ~73
* 25 characters (Yellow): ~74
* 40 characters (Light Blue): ~74
* 55 characters (Blue): ~73
* 70 characters (Dark Blue): ~64
* Trend: Similar to Qwen-2.5-MATH-7B, accuracy is high until 55 characters, then decreases at 70 characters.
* **Qwen-2.5-MATH-1.5B:**
* 0 characters (Red): ~64
* 10 characters (Orange): ~64
* 25 characters (Yellow): ~65
* 40 characters (Light Blue): ~65
* 55 characters (Blue): ~65
* 70 characters (Dark Blue): ~62
* Trend: Accuracy is relatively stable across all input lengths, with a slight dip at 70 characters.
* **DS-R1-Distill-Qwen-7B:**
* 0 characters (Red): ~52
* 10 characters (Orange): ~53
* 25 characters (Yellow): ~53
* 40 characters (Light Blue): ~53
* 55 characters (Blue): ~52
* 70 characters (Dark Blue): ~46
* Trend: Accuracy is lower compared to the previous models and decreases more noticeably at 70 characters.
* **DS-math-7b-instruct:**
* 0 characters (Red): ~40
* 10 characters (Orange): ~40
* 25 characters (Yellow): ~41
* 40 characters (Light Blue): ~41
* 55 characters (Blue): ~41
* 70 characters (Dark Blue): ~34
* Trend: The lowest accuracy among the models, with a significant drop at 70 characters.
### Key Observations
* Qwen-2.5-MATH-7B and GPT-4o-mini achieve the highest accuracy overall.
* DS-math-7b-instruct has the lowest accuracy.
* For most models, accuracy tends to decrease when the input length is 70 characters.
* The models Qwen-2.5-MATH-7B and GPT-4o-mini show very similar performance across all input lengths.
### Interpretation
The chart illustrates the performance of different language models on the MATH-500 dataset, specifically focusing on how accuracy changes with varying input lengths. The results suggest that some models (Qwen-2.5-MATH-7B and GPT-4o-mini) are more robust and accurate than others (DS-math-7b-instruct). The decrease in accuracy at 70 characters for most models could indicate a limitation in handling longer inputs or a change in the nature of the problems when more context is provided. The similar performance of Qwen-2.5-MATH-7B and GPT-4o-mini might indicate similar architectures or training methodologies. The lower performance of the distilled models (DS-R1-Distill-Qwen-7B and DS-math-7b-instruct) is expected, as distillation often leads to a trade-off between model size/speed and accuracy.