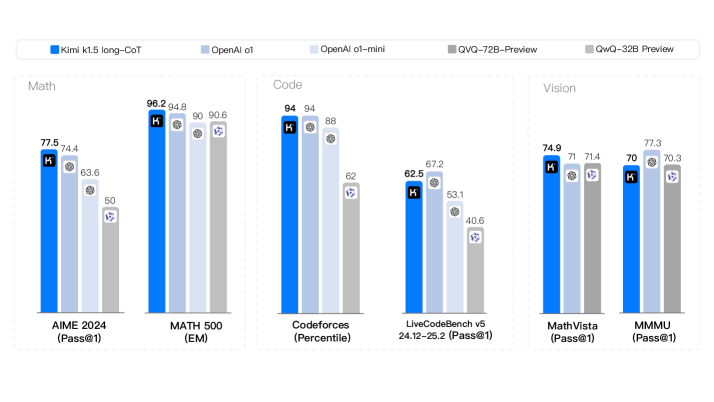
## Bar Chart: AI Model Performance Across Math, Code, and Vision Tasks
### Overview
The image is a grouped bar chart comparing the performance of five AI models (Kimi k1.5-long-CoT, OpenAI o1, OpenAI o1-mini, QVQ-72B-Preview, QwQ-32B Preview) across three categories: **Math**, **Code**, and **Vision**. Each category contains specific benchmarks (e.g., AIME 2024, Codeforces, MathVista) with numerical scores. The chart uses distinct colors for each model, as indicated in the legend at the top.
### Components/Axes
- **X-Axis (Categories)**:
- **Math**: AIME 2024 (Pass@1), MATH 500 (EM)
- **Code**: Codeforces (Percentile), LiveCodeBench v5 24.12-25.2 (Pass@1)
- **Vision**: MathVista (Pass@1), MMMU (Pass@1)
- **Y-Axis (Scores)**: Numerical values (approximate, based on bar heights).
- **Legend**:
- **Blue**: Kimi k1.5-long-CoT
- **Light Blue**: OpenAI o1
- **Gray**: OpenAI o1-mini
- **Dark Gray**: QVQ-72B-Preview
- **Purple**: QwQ-32B Preview
### Detailed Analysis
#### Math Category
- **AIME 2024 (Pass@1)**:
- Kimi: 77.5
- OpenAI o1: 74.4
- OpenAI o1-mini: 63.6
- QVQ-72B-Preview: 50
- QwQ-32B Preview: 50
- **MATH 500 (EM)**:
- Kimi: 96.2
- OpenAI o1: 94.8
- OpenAI o1-mini: 90
- QVQ-72B-Preview: 90.6
- QwQ-32B Preview: 90.6
#### Code Category
- **Codeforces (Percentile)**:
- Kimi: 94
- OpenAI o1: 94
- OpenAI o1-mini: 88
- QVQ-72B-Preview: 62.5
- QwQ-32B Preview: 62
- **LiveCodeBench v5 24.12-25.2 (Pass@1)**:
- Kimi: 67.2
- OpenAI o1: 53.1
- OpenAI o1-mini: 40.6
- QVQ-72B-Preview: 40.6
- QwQ-32B Preview: 40.6
#### Vision Category
- **MathVista (Pass@1)**:
- Kimi: 74.9
- OpenAI o1: 71
- OpenAI o1-mini: 71.4
- QVQ-72B-Preview: 70
- QwQ-32B Preview: 70.3
- **MMMU (Pass@1)**:
- Kimi: 70
- OpenAI o1: 77.3
- OpenAI o1-mini: 70.3
- QVQ-72B-Preview: 70.3
- QwQ-32B Preview: 70.3
### Key Observations
1. **Math Performance**:
- Kimi and OpenAI o1 dominate in **AIME 2024** and **MATH 500**, with Kimi achieving the highest scores (96.2 and 77.5, respectively).
- QVQ-72B-Preview and QwQ-32B Preview underperform in **AIME 2024** (50) but match OpenAI o1-mini in **MATH 500** (90.6).
2. **Code Performance**:
- Kimi and OpenAI o1 excel in **Codeforces** (94 and 94, respectively), while QVQ-72B-Preview and QwQ-32B Preview lag significantly (62.5 and 62).
- In **LiveCodeBench**, Kimi leads (67.2), but OpenAI o1-mini and QwQ-32B Preview score poorly (40.6).
3. **Vision Performance**:
- Kimi and OpenAI o1 perform similarly in **MathVista** (74.9 vs. 71), while QwQ-32B Preview scores slightly higher (70.3).
- In **MMMU**, OpenAI o1 leads (77.3), but all models except Kimi score 70.3 or lower.
### Interpretation
- **Kimi k1.5-long-CoT** consistently outperforms other models in **Math** and **Code** tasks, suggesting strong reasoning and problem-solving capabilities.
- **OpenAI o1** excels in **Codeforces** and **MMMU**, indicating robust coding and vision capabilities. However, its performance in **LiveCodeBench** is weaker compared to Kimi.
- **QVQ-72B-Preview** and **QwQ-32B Preview** show mixed results: they match OpenAI o1-mini in **MATH 500** but underperform in **Codeforces** and **LiveCodeBench**. Their **Vision** scores are comparable to other models.
- **OpenAI o1-mini** lags in **Code** tasks (e.g., 40.6 in **LiveCodeBench**) but performs adequately in **Vision**.
### Notable Trends
- **Math and Code**: Kimi and OpenAI o1 dominate, while QVQ-72B-Preview and QwQ-32B Preview struggle in **Code** tasks.
- **Vision**: OpenAI o1 leads in **MMMU**, but all models score similarly in **MathVista**.
- **Outliers**: QVQ-72B-Preview and QwQ-32B Preview have the lowest scores in **LiveCodeBench** (40.6), suggesting potential limitations in coding benchmarks.
This chart highlights the varying strengths of AI models across domains, with Kimi and OpenAI o1 leading in **Math** and **Code**, while **Vision** performance is more evenly distributed.