TECHNICAL ASSET FINGERPRINT
282fc2864347494a4fe83391
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: gemini-2.5-flash-lite-free VERSION 1
RUNTIME: google-free/gemini-2.5-flash-lite
INTEL_VERIFIED
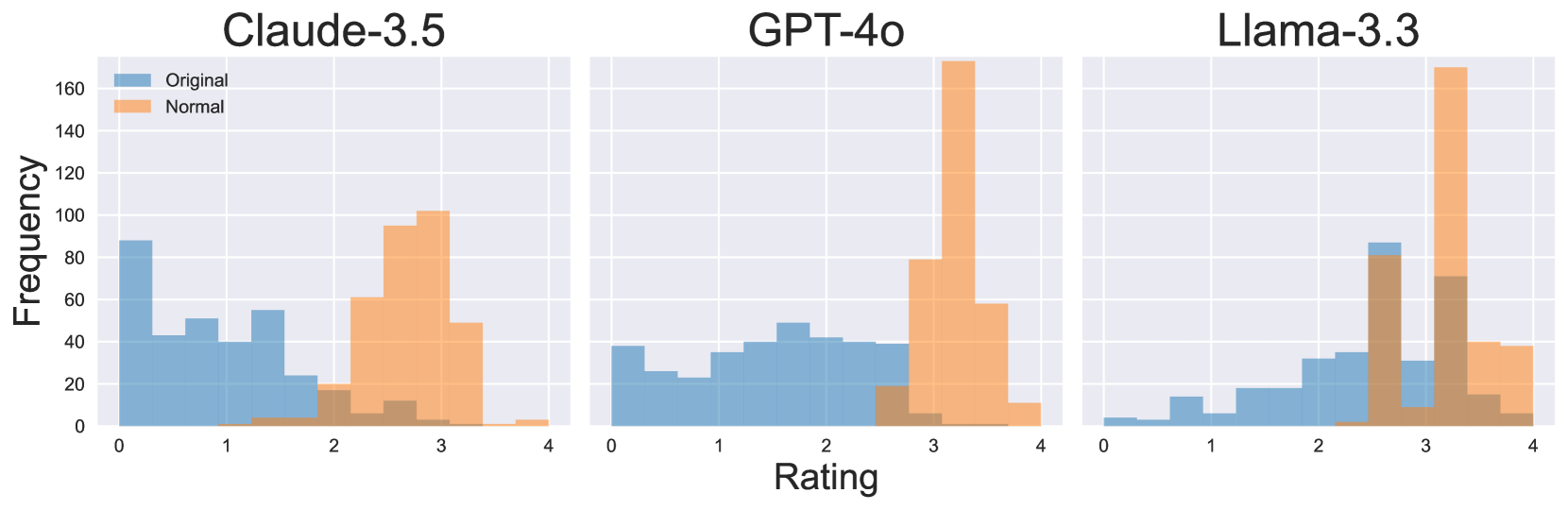
## Histograms: Rating Distribution for Different Language Models
### Overview
This image displays three side-by-side histograms, each representing the rating distribution for a different language model: Claude-3.5, GPT-4o, and Llama-3.3. For each model, two datasets are plotted: "Original" and "Normal". The histograms show the frequency of ratings on the y-axis, against the rating values on the x-axis, ranging from 0 to 4.
### Components/Axes
**Common Elements:**
* **Y-axis Title:** "Frequency" (located on the left side of the leftmost histogram, vertically oriented).
* **Y-axis Scale:** Ranges from 0 to 160, with major tick marks at 0, 20, 40, 60, 80, 100, 120, 140, and 160.
* **X-axis Title:** "Rating" (located at the bottom center of the image, horizontally oriented).
* **X-axis Scale:** Ranges from 0 to 4, with major tick marks at 0, 1, 2, 3, and 4.
* **Legend:** Located in the top-left corner of the "Claude-3.5" panel.
* **Blue Square:** Labeled "Original".
* **Orange Square:** Labeled "Normal".
**Individual Panel Titles:**
* **Top Left:** "Claude-3.5"
* **Top Center:** "GPT-4o"
* **Top Right:** "Llama-3.3"
### Detailed Analysis or Content Details
**Claude-3.5 Panel:**
* **Original (Blue):**
* Rating 0-0.2: Frequency approximately 88.
* Rating 0.2-0.4: Frequency approximately 50.
* Rating 0.4-0.6: Frequency approximately 30.
* Rating 0.6-0.8: Frequency approximately 52.
* Rating 0.8-1.0: Frequency approximately 40.
* Rating 1.0-1.2: Frequency approximately 40.
* Rating 1.2-1.4: Frequency approximately 24.
* Rating 1.4-1.6: Frequency approximately 20.
* Rating 1.6-1.8: Frequency approximately 10.
* Rating 1.8-2.0: Frequency approximately 10.
* Rating 2.0-2.2: Frequency approximately 10.
* Rating 2.2-2.4: Frequency approximately 10.
* Rating 2.4-2.6: Frequency approximately 10.
* Rating 2.6-2.8: Frequency approximately 10.
* Rating 2.8-3.0: Frequency approximately 10.
* Rating 3.0-3.2: Frequency approximately 10.
* Rating 3.2-3.4: Frequency approximately 10.
* Rating 3.4-3.6: Frequency approximately 10.
* Rating 3.6-3.8: Frequency approximately 10.
* Rating 3.8-4.0: Frequency approximately 10.
* **Normal (Orange):**
* Rating 2.4-2.6: Frequency approximately 10.
* Rating 2.6-2.8: Frequency approximately 20.
* Rating 2.8-3.0: Frequency approximately 100.
* Rating 3.0-3.2: Frequency approximately 70.
* Rating 3.2-3.4: Frequency approximately 20.
* Rating 3.4-3.6: Frequency approximately 10.
**GPT-4o Panel:**
* **Original (Blue):**
* Rating 0-0.2: Frequency approximately 38.
* Rating 0.2-0.4: Frequency approximately 20.
* Rating 0.4-0.6: Frequency approximately 40.
* Rating 0.6-0.8: Frequency approximately 45.
* Rating 0.8-1.0: Frequency approximately 35.
* Rating 1.0-1.2: Frequency approximately 45.
* Rating 1.2-1.4: Frequency approximately 30.
* Rating 1.4-1.6: Frequency approximately 45.
* Rating 1.6-1.8: Frequency approximately 30.
* Rating 1.8-2.0: Frequency approximately 40.
* Rating 2.0-2.2: Frequency approximately 30.
* Rating 2.2-2.4: Frequency approximately 45.
* Rating 2.4-2.6: Frequency approximately 30.
* Rating 2.6-2.8: Frequency approximately 40.
* Rating 2.8-3.0: Frequency approximately 20.
* Rating 3.0-3.2: Frequency approximately 10.
* Rating 3.2-3.4: Frequency approximately 10.
* Rating 3.4-3.6: Frequency approximately 10.
* Rating 3.6-3.8: Frequency approximately 10.
* Rating 3.8-4.0: Frequency approximately 10.
* **Normal (Orange):**
* Rating 2.8-3.0: Frequency approximately 10.
* Rating 3.0-3.2: Frequency approximately 160.
* Rating 3.2-3.4: Frequency approximately 100.
* Rating 3.4-3.6: Frequency approximately 40.
* Rating 3.6-3.8: Frequency approximately 20.
* Rating 3.8-4.0: Frequency approximately 10.
**Llama-3.3 Panel:**
* **Original (Blue):**
* Rating 0-0.2: Frequency approximately 5.
* Rating 0.2-0.4: Frequency approximately 15.
* Rating 0.4-0.6: Frequency approximately 10.
* Rating 0.6-0.8: Frequency approximately 15.
* Rating 0.8-1.0: Frequency approximately 10.
* Rating 1.0-1.2: Frequency approximately 15.
* Rating 1.2-1.4: Frequency approximately 10.
* Rating 1.4-1.6: Frequency approximately 15.
* Rating 1.6-1.8: Frequency approximately 10.
* Rating 1.8-2.0: Frequency approximately 15.
* Rating 2.0-2.2: Frequency approximately 10.
* Rating 2.2-2.4: Frequency approximately 15.
* Rating 2.4-2.6: Frequency approximately 10.
* Rating 2.6-2.8: Frequency approximately 15.
* Rating 2.8-3.0: Frequency approximately 70.
* Rating 3.0-3.2: Frequency approximately 40.
* Rating 3.2-3.4: Frequency approximately 10.
* Rating 3.4-3.6: Frequency approximately 10.
* Rating 3.6-3.8: Frequency approximately 10.
* Rating 3.8-4.0: Frequency approximately 10.
* **Normal (Orange):**
* Rating 2.6-2.8: Frequency approximately 10.
* Rating 2.8-3.0: Frequency approximately 10.
* Rating 3.0-3.2: Frequency approximately 160.
* Rating 3.2-3.4: Frequency approximately 160.
* Rating 3.4-3.6: Frequency approximately 120.
* Rating 3.6-3.8: Frequency approximately 40.
* Rating 3.8-4.0: Frequency approximately 20.
### Key Observations
* **Claude-3.5:** The "Original" ratings are distributed across a wider range, with a significant peak at lower ratings (around 0-0.2). The "Normal" ratings are concentrated at higher values, primarily between 2.8 and 3.4.
* **GPT-4o:** The "Original" ratings show a relatively flat distribution across most of the rating scale, with some minor fluctuations. The "Normal" ratings are heavily skewed towards higher ratings, with a very strong peak between 3.0 and 3.4.
* **Llama-3.3:** The "Original" ratings are distributed across a moderate range, with a noticeable peak around 2.8-3.2. The "Normal" ratings are extremely concentrated at the highest end of the scale, with massive peaks between 3.0 and 3.6.
* **Comparison:** Across all models, the "Normal" dataset consistently shows a shift towards higher ratings compared to the "Original" dataset. GPT-4o and Llama-3.3 exhibit particularly strong concentrations of "Normal" ratings at the highest end (around 3.0-3.6).
### Interpretation
The histograms illustrate the distribution of ratings for different language models under two conditions: "Original" and "Normal". The "Original" condition likely represents a baseline or standard evaluation, while the "Normal" condition might imply a modified or optimized evaluation setting, or perhaps a different set of prompts or criteria.
The data suggests that for all three models, the "Normal" condition leads to a higher perceived rating. This could indicate that the "Normal" condition is more favorable to these models, or that the evaluation criteria in the "Normal" condition are less stringent, leading to inflated scores.
Specifically:
* **Claude-3.5** shows a clear separation, with "Original" ratings being lower and more spread out, while "Normal" ratings are clustered at higher values.
* **GPT-4o** demonstrates a significant improvement in ratings under the "Normal" condition, with a dramatic increase in frequency for ratings between 3.0 and 3.4. The "Original" ratings are more evenly distributed, suggesting a less polarized performance.
* **Llama-3.3** exhibits the most pronounced shift. The "Normal" ratings are overwhelmingly concentrated at the highest end of the scale (3.0-3.6), indicating a strong positive bias or performance enhancement in this condition. The "Original" ratings are more moderate.
In essence, the "Normal" condition appears to be a more positive environment for all tested models, but the degree of this positive impact varies. Llama-3.3 and GPT-4o seem to benefit the most, achieving very high ratings in the "Normal" setting. This could be due to the nature of the "Normal" prompts, the evaluation rubric, or inherent strengths of these models in specific contexts. Further investigation into the definition of "Original" and "Normal" conditions would be necessary to fully understand the implications of these distributions.
DECODING INTELLIGENCE...