## Network Diagram: COCONUT Model with k=1 and k=2
### Overview
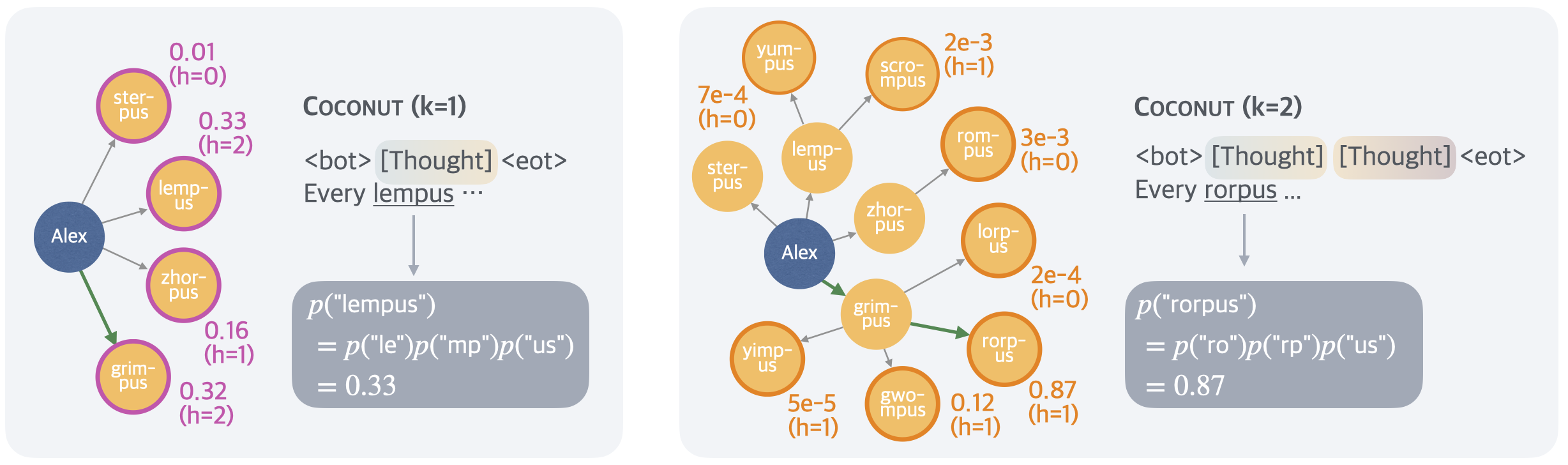
The image presents two network diagrams illustrating the COCONUT model with different values of 'k' (k=1 and k=2). Each diagram shows a network of nodes representing word fragments or units, connected by edges. The nodes are labeled with word fragments, and the edges are annotated with probabilities and 'h' values. The diagrams demonstrate how the model generates sequences of word fragments.
### Components/Axes
**General Components:**
* **Nodes:** Represent word fragments (e.g., "ster-pus", "lemp-us", "Alex").
* **Edges:** Connect nodes, indicating transitions between word fragments. Edges are annotated with probabilities.
* **Node Color:** The node "Alex" is blue, while all other word fragment nodes are orange/yellow.
* **Edge Color:** Most edges are gray, but some are green, indicating a specific path.
* **'h' Value:** Indicates the hidden state or context.
* **COCONUT (k=1/k=2):** Titles indicating the model configuration.
* **<bot> [Thought] <eot>:** Represents the beginning-of-text, the thought, and the end-of-text markers.
* **Every lempus/rorpus...:** Indicates the generated sequence.
* **p("lempus")/p("rorpus"):** Probability calculations for the generated sequences.
**Left Diagram (k=1):**
* **Nodes:** Alex, ster-pus, lemp-us, zhor-pus, grim-pus.
* **Probabilities:**
* ster-pus: 0.01 (h=0), 0.33 (h=2)
* grim-pus: 0.16 (h=1), 0.32 (h=2)
* **Edge Color:** The edge from Alex to grim-pus is green.
* **Probability Calculation:**
* p("lempus") = p("le")p("mp")p("us") = 0.33
**Right Diagram (k=2):**
* **Nodes:** Alex, yum-pus, ster-pus, lemp-us, scro-mpus, rom-pus, zhor-pus, lorp-us, grim-pus, yimp-us, gwo-mpus, rorp-us.
* **Probabilities:**
* yum-pus: 7e-4 (h=0)
* scro-mpus: 2e-3 (h=1)
* rom-pus: 3e-3 (h=0)
* lorp-us: 2e-4 (h=0)
* yimp-us: 5e-5 (h=1)
* gwo-mpus: 0.12 (h=1)
* rorp-us: 0.87 (h=1)
* **Edge Color:** The edge from Alex to grim-pus and from grim-pus to rorp-us are green.
* **Probability Calculation:**
* p("rorpus") = p("ro")p("rp")p("us") = 0.87
### Detailed Analysis or Content Details
**Left Diagram (k=1):**
* The network starts from the "Alex" node.
* "Alex" connects to "ster-pus", "lemp-us", "zhor-pus", and "grim-pus".
* The path from "Alex" to "grim-pus" is highlighted in green.
* The probability of generating "lempus" is calculated as 0.33.
**Right Diagram (k=2):**
* The network starts from the "Alex" node.
* "Alex" connects to "yum-pus", "ster-pus", "lemp-us", "zhor-pus", "yimp-us", and "grim-pus".
* The path from "Alex" to "grim-pus" to "rorp-us" is highlighted in green.
* The probability of generating "rorpus" is calculated as 0.87.
### Key Observations
* The value of 'k' influences the complexity of the network and the generated sequences.
* Higher 'k' (k=2) results in a more complex network with more nodes and connections.
* The green edges highlight specific paths through the network, likely representing the most probable or relevant sequences.
* The probability calculations show how the model computes the likelihood of generating specific word fragments.
### Interpretation
The diagrams illustrate a probabilistic model (COCONUT) for generating word fragments or sequences. The 'k' parameter controls the order of the model, with higher values allowing for longer-range dependencies. The network structure represents the possible transitions between word fragments, and the edge probabilities quantify the likelihood of these transitions. The green paths highlight the most probable sequences, and the probability calculations demonstrate how the model computes the overall likelihood of generating specific words or phrases. The model seems to be learning the structure of words and their probabilities based on the training data. The difference in the generated sequences ("lempus" vs. "rorpus") and their probabilities suggests that the model adapts its output based on the 'k' parameter, effectively capturing different levels of linguistic complexity.