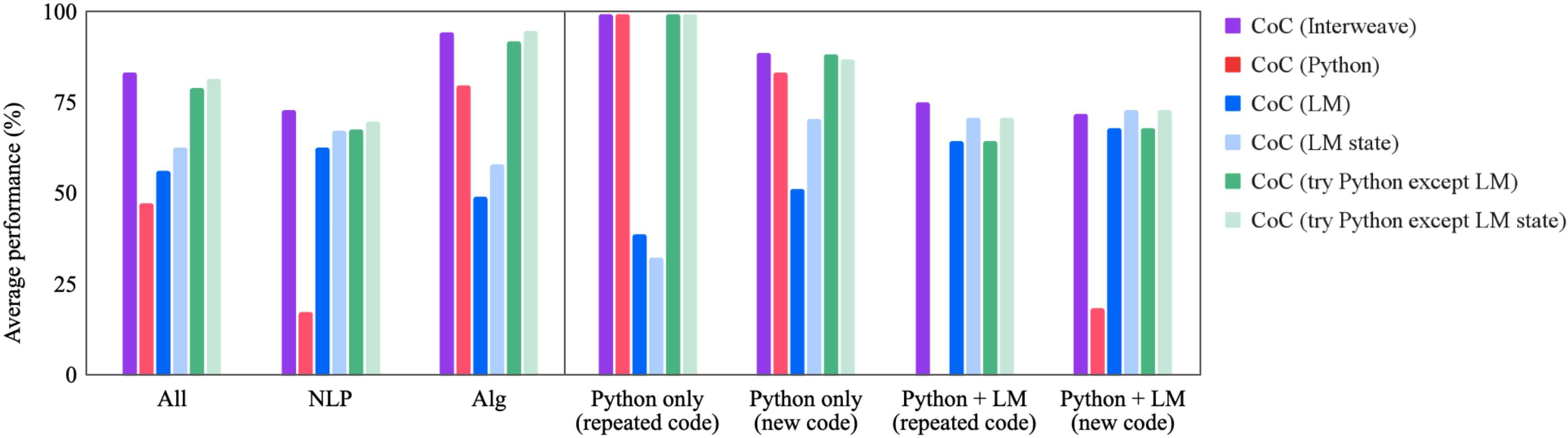
## Grouped Bar Chart: Average Performance (%) by Method and Task Category
### Overview
The image displays a grouped bar chart comparing the average performance (in percentage) of six different "CoC" (Chain-of-Code) methods across seven distinct task categories. The chart is divided into two main panels by a vertical line, separating broader task categories (left) from more specific Python-related task categories (right).
### Components/Axes
* **Y-Axis:** Labeled "Average performance (%)". The scale runs from 0 to 100, with major tick marks at 0, 25, 50, 75, and 100.
* **X-Axis:** Contains seven categorical groups. From left to right:
1. All
2. NLP
3. Alg
4. Python only (repeated code)
5. Python only (new code)
6. Python + LM (repeated code)
7. Python + LM (new code)
* **Legend:** Positioned on the right side of the chart. It defines six data series by color:
* Purple square: CoC (Interweave)
* Red square: CoC (Python)
* Blue square: CoC (LM)
* Light Blue square: CoC (LM state)
* Green square: CoC (try Python except LM)
* Light Green square: CoC (try Python except LM state)
### Detailed Analysis
Performance values are approximate, estimated from bar heights relative to the y-axis.
**Left Panel (General Categories):**
* **All:**
* CoC (Interweave) [Purple]: ~85%
* CoC (Python) [Red]: ~48%
* CoC (LM) [Blue]: ~55%
* CoC (LM state) [Light Blue]: ~63%
* CoC (try Python except LM) [Green]: ~79%
* CoC (try Python except LM state) [Light Green]: ~82%
* **NLP:**
* CoC (Interweave) [Purple]: ~74%
* CoC (Python) [Red]: ~18% (notably low)
* CoC (LM) [Blue]: ~63%
* CoC (LM state) [Light Blue]: ~68%
* CoC (try Python except LM) [Green]: ~69%
* CoC (try Python except LM state) [Light Green]: ~71%
* **Alg:**
* CoC (Interweave) [Purple]: ~95%
* CoC (Python) [Red]: ~80%
* CoC (LM) [Blue]: ~49%
* CoC (LM state) [Light Blue]: ~58%
* CoC (try Python except LM) [Green]: ~92%
* CoC (try Python except LM state) [Light Green]: ~96%
**Right Panel (Python-Specific Categories):**
* **Python only (repeated code):**
* CoC (Interweave) [Purple]: ~100%
* CoC (Python) [Red]: ~100%
* CoC (LM) [Blue]: ~39%
* CoC (LM state) [Light Blue]: ~32%
* CoC (try Python except LM) [Green]: ~100%
* CoC (try Python except LM state) [Light Green]: ~100%
* **Python only (new code):**
* CoC (Interweave) [Purple]: ~89%
* CoC (Python) [Red]: ~83%
* CoC (LM) [Blue]: ~51%
* CoC (LM state) [Light Blue]: ~71%
* CoC (try Python except LM) [Green]: ~89%
* CoC (try Python except LM state) [Light Green]: ~88%
* **Python + LM (repeated code):**
* CoC (Interweave) [Purple]: ~75%
* CoC (Python) [Red]: Bar is absent or at 0%.
* CoC (LM) [Blue]: ~64%
* CoC (LM state) [Light Blue]: ~72%
* CoC (try Python except LM) [Green]: ~65%
* CoC (try Python except LM state) [Light Green]: ~72%
* **Python + LM (new code):**
* CoC (Interweave) [Purple]: ~73%
* CoC (Python) [Red]: ~19%
* CoC (LM) [Blue]: ~68%
* CoC (LM state) [Light Blue]: ~74%
* CoC (try Python except LM) [Green]: ~68%
* CoC (try Python except LM state) [Light Green]: ~74%
### Key Observations
1. **Method Dominance:** CoC (Interweave) [Purple] is consistently a top performer across all categories, never dropping below ~73%.
2. **Task-Specific Performance:** CoC (Python) [Red] shows extreme variance. It achieves near-perfect scores (~100%) in "Python only (repeated code)" but performs very poorly in NLP (~18%) and "Python + LM (new code)" (~19%).
3. **Hybrid Method Strength:** The "try Python except LM" methods (Green and Light Green) are strong and consistent performers, often matching or nearly matching the top-performing Interweave method, especially in the "Alg" and "Python only" categories.
4. **LM-Only Weakness:** The pure language model methods, CoC (LM) [Blue] and CoC (LM state) [Light Blue], generally underperform compared to the hybrid and Interweave methods, particularly in the "Python only (repeated code)" category where they score below 40%.
5. **Impact of Code Novelty:** For most methods, performance on "new code" tasks is slightly lower than on "repeated code" tasks within the same category (e.g., Python only). The exception is the pure LM methods, which sometimes show improvement on new code.
6. **Missing Data:** The CoC (Python) [Red] bar is absent for "Python + LM (repeated code)", indicating a score of 0% or that the method was not applicable.
### Interpretation
This chart evaluates different strategies for a "Chain-of-Code" (CoC) prompting or reasoning framework. The data suggests that:
* **Interweaving is Robust:** The "Interweave" strategy appears to be the most robust and generalizable approach, maintaining high performance regardless of the task domain (NLP, Algorithms, Python).
* **Specialization vs. Generalization:** The "CoC (Python)" method is highly specialized. It excels when the task is purely Python code repetition but fails catastrophically when the task involves natural language or requires combining Python with a language model. This indicates it lacks generalization capability.
* **Hybrid Approaches are Effective:** The "try Python except LM" strategies demonstrate the value of a hybrid, fallback approach. They leverage Python execution when possible but can fall back to the language model, achieving performance that rivals the top method in many cases. This suggests a practical and reliable implementation strategy.
* **Pure LM Limitations:** Relying solely on a language model (LM or LM state) yields suboptimal performance compared to methods that incorporate code execution or sophisticated interleaving. This underscores the benefit of augmenting LMs with external tools or structured reasoning steps for these task types.
* **Task Nature Matters:** The dramatic performance swings for some methods highlight that the underlying nature of the task (e.g., algorithmic vs. linguistic, code repetition vs. generation) is a critical factor in selecting the appropriate CoC strategy. There is no single best method for all scenarios, though Interweave comes closest.