\n
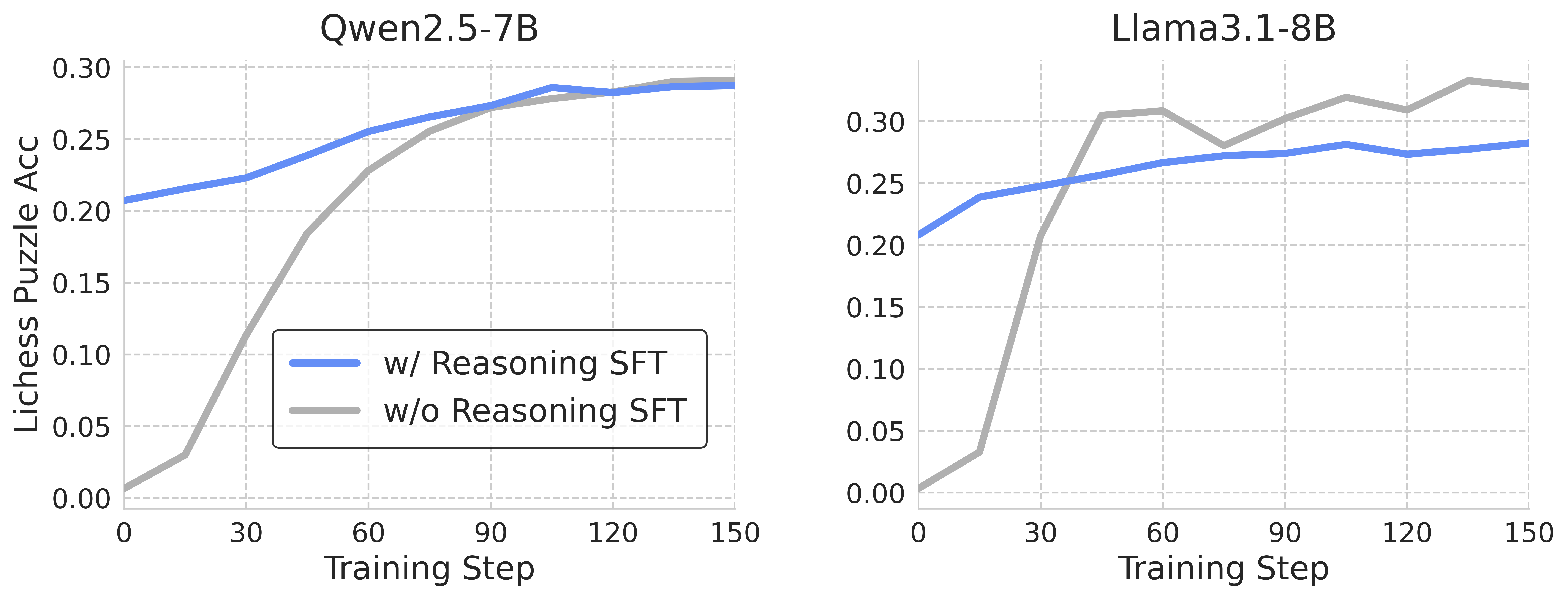
## Line Chart: Lichess Puzzle Accuracy vs. Training Step for Two Models
### Overview
This image presents two line charts comparing the performance of two language models, Qwen2.5-7B and Llama3.1-8B, on the Lichess puzzle accuracy task during training. Each chart displays two lines representing models trained *with* reasoning Supervised Fine-Tuning (SFT) and *without* reasoning SFT. The x-axis represents the training step, and the y-axis represents the Lichess puzzle accuracy.
### Components/Axes
* **X-axis (Both Charts):** "Training Step", ranging from 0 to 150. Gridlines are present at intervals of 30.
* **Y-axis (Both Charts):** "Lichess Puzzle Acc", ranging from 0.00 to 0.30. Gridlines are present at intervals of 0.05.
* **Chart 1 Title:** "Qwen2.5-7B"
* **Chart 2 Title:** "Llama3.1-8B"
* **Legend (Both Charts):** Located in the bottom-left corner.
* Blue Line: "w/ Reasoning SFT"
* Gray Line: "w/o Reasoning SFT"
### Detailed Analysis or Content Details
**Qwen2.5-7B Chart:**
* **w/ Reasoning SFT (Blue Line):** The line starts at approximately 0.02 at Training Step 0. It increases rapidly to around 0.22 at Training Step 30. The line continues to increase, leveling off around 0.28-0.29 between Training Steps 90 and 150.
* **w/o Reasoning SFT (Gray Line):** The line starts at approximately 0.00 at Training Step 0. It increases more slowly than the blue line, reaching around 0.15 at Training Step 30. The line continues to increase, reaching approximately 0.27 at Training Step 90, and then fluctuates between 0.27 and 0.29 until Training Step 150.
**Llama3.1-8B Chart:**
* **w/ Reasoning SFT (Blue Line):** The line starts at approximately 0.02 at Training Step 0. It increases rapidly to around 0.24 at Training Step 30. The line plateaus around 0.26-0.27 between Training Steps 60 and 150, with some minor fluctuations.
* **w/o Reasoning SFT (Gray Line):** The line starts at approximately 0.01 at Training Step 0. It increases rapidly to around 0.20 at Training Step 30. The line continues to increase, reaching approximately 0.31 at Training Step 60, then decreases to around 0.28 at Training Step 90, and fluctuates between 0.28 and 0.31 until Training Step 150.
### Key Observations
* For both models, training *with* reasoning SFT consistently results in higher Lichess puzzle accuracy than training *without* reasoning SFT, especially in the early stages of training.
* The Qwen2.5-7B model appears to reach a plateau in accuracy earlier than the Llama3.1-8B model.
* The Llama3.1-8B model *without* reasoning SFT shows a significant peak in accuracy around Training Step 60, followed by a slight decrease and then stabilization. This is a notable outlier.
* The difference in performance between the two SFT strategies diminishes as training progresses, suggesting that the benefits of reasoning SFT may decrease over time.
### Interpretation
The data suggests that incorporating reasoning SFT significantly improves the ability of both Qwen2.5-7B and Llama3.1-8B to solve Lichess puzzles. This indicates that explicitly training the models to reason enhances their performance on this task. The plateau observed in Qwen2.5-7B suggests that the model may have reached its capacity for improvement on this specific task with the given training data and methodology. The peak and subsequent stabilization in Llama3.1-8B (without reasoning SFT) could be due to overfitting to a specific subset of puzzles or a temporary convergence during training. The diminishing difference between the two SFT strategies as training progresses could indicate that the benefits of reasoning SFT are more pronounced during the initial stages of learning, and that other factors become more important as the models become more proficient. Further investigation would be needed to understand the cause of the Llama3.1-8B outlier.