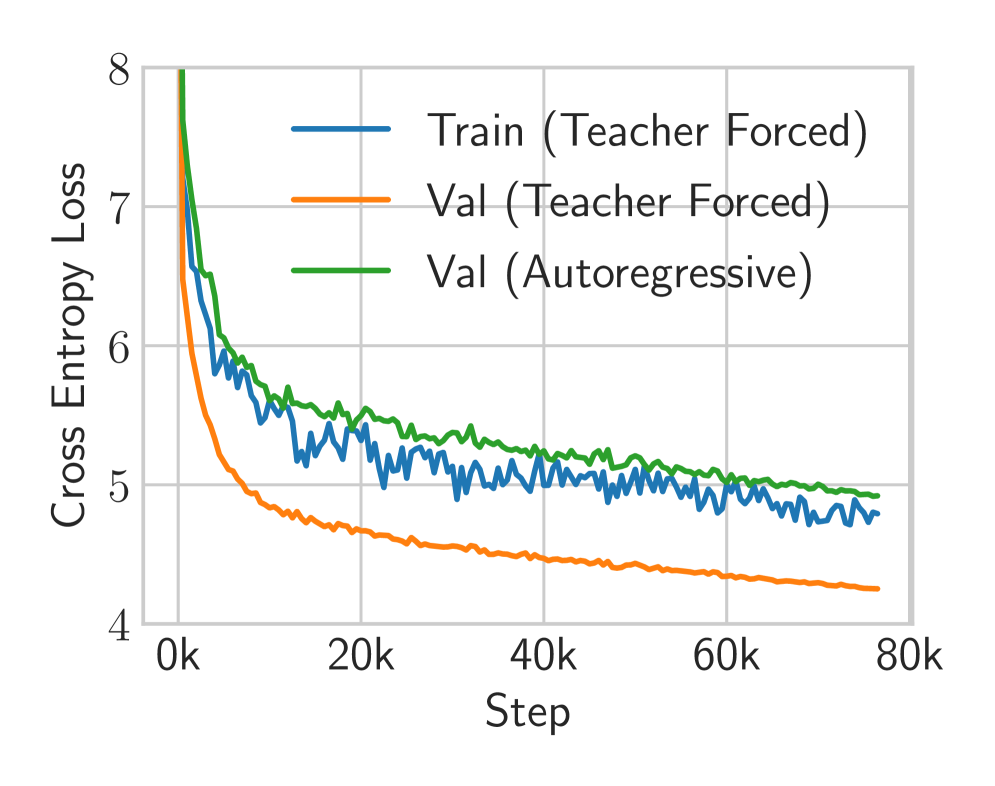
## Chart: Cross Entropy Loss vs. Step
### Overview
The image is a line chart displaying the cross-entropy loss over training steps for three different configurations: Train (Teacher Forced), Val (Teacher Forced), and Val (Autoregressive). The x-axis represents the training step, and the y-axis represents the cross-entropy loss.
### Components/Axes
* **X-axis:** "Step" with markers at 0k, 20k, 40k, 60k, and 80k.
* **Y-axis:** "Cross Entropy Loss" with markers at 4, 5, 6, 7, and 8.
* **Legend:** Located at the top-right of the chart.
* Blue line: "Train (Teacher Forced)"
* Orange line: "Val (Teacher Forced)"
* Green line: "Val (Autoregressive)"
### Detailed Analysis
* **Train (Teacher Forced) - Blue Line:**
* Trend: The line slopes downward, indicating a decrease in cross-entropy loss as the training step increases.
* Starting point: Approximately 7.2 at step 0k.
* Ending point: Approximately 4.9 at step 80k.
* The line fluctuates more than the other two.
* **Val (Teacher Forced) - Orange Line:**
* Trend: The line slopes downward, indicating a decrease in cross-entropy loss as the training step increases.
* Starting point: Approximately 6.8 at step 0k.
* Ending point: Approximately 4.4 at step 80k.
* The line is smoother than the other two.
* **Val (Autoregressive) - Green Line:**
* Trend: The line slopes downward, indicating a decrease in cross-entropy loss as the training step increases.
* Starting point: Approximately 7.9 at step 0k.
* Ending point: Approximately 4.9 at step 80k.
* The line fluctuates more than the orange line, but less than the blue line.
### Key Observations
* All three lines show a decreasing trend in cross-entropy loss as the training step increases.
* The "Val (Teacher Forced)" line (orange) consistently has the lowest cross-entropy loss after the initial steps.
* The "Train (Teacher Forced)" line (blue) and "Val (Autoregressive)" line (green) converge to approximately the same cross-entropy loss at the end of the training steps.
### Interpretation
The chart illustrates the learning process of a model under different training and validation configurations. The decreasing cross-entropy loss indicates that the model is learning and improving its performance over time. The "Val (Teacher Forced)" configuration appears to be the most effective, as it achieves the lowest validation loss. The convergence of the "Train (Teacher Forced)" and "Val (Autoregressive)" lines suggests that the model's performance is similar under these two configurations at the end of the training process. The fluctuations in the "Train (Teacher Forced)" and "Val (Autoregressive)" lines may indicate some instability or sensitivity to the training data.