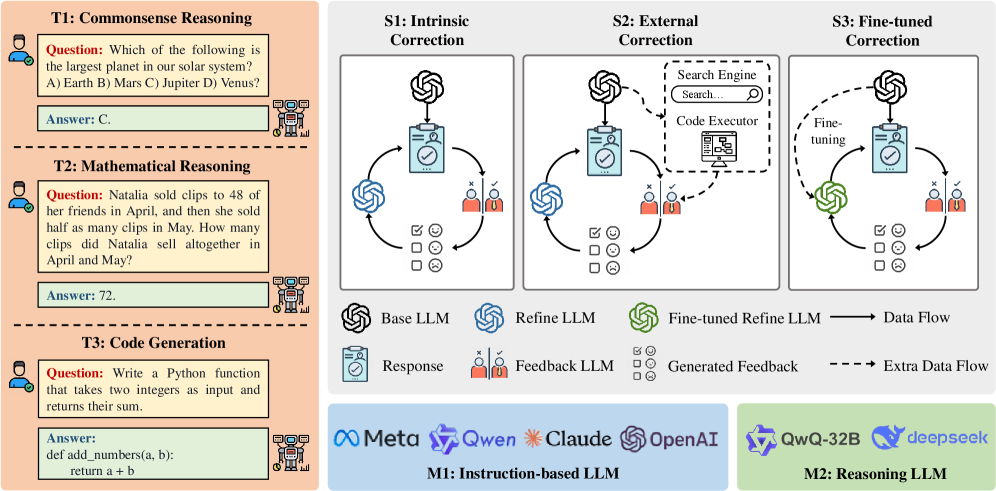
## Diagram: LLM Correction and Reasoning Process
### Overview
The image illustrates a comparison between instruction-based and reasoning-based Large Language Models (LLMs), demonstrating different correction mechanisms applied to instruction-based LLMs. The diagram highlights intrinsic correction, external correction, and fine-tuned correction strategies. The image is divided into 3 main sections: Task Examples (T1, T2, T3), Correction Strategies (S1, S2, S3), and Model Types (M1, M2).
### Components/Axes
* **Task Examples (Left Column)**: Shows examples of tasks LLMs might encounter, including Commonsense Reasoning (T1), Mathematical Reasoning (T2), and Code Generation (T3).
* **Correction Strategies (Top Right)**: Illustrates three correction methods: Intrinsic Correction (S1), External Correction (S2), and Fine-tuned Correction (S3). Each correction strategy shows a looping process where a Base LLM produces a Response, Feedback is generated (either internally or externally), and then used to refine the LLM.
* **Model Types (Bottom)**: Differentiates between Instruction-based LLMs (M1) and Reasoning LLMs (M2) by showing logos of companies and specific models within each category.
* **Legend**:
* Base LLM (Swirl Symbol): Represents the initial LLM.
* Refine LLM (Swirl Symbol): Indicates the LLM after the initial refinement process.
* Fine-tuned Refine LLM (Green Swirl Symbol): Represents the final refined LLM after fine-tuning.
* Response (Document Icon): Represents the output or answer provided by the LLM.
* Feedback LLM (Avatar): Person providing the feedback.
* Generated Feedback (Checklist): Represents the feedback used to refine the model.
* Data Flow (Solid Arrow): Indicates the flow of data between components.
* Extra Data Flow (Dashed Arrow): Indicates auxiliary or external data flow.
### Detailed Analysis
**Task Examples (Left)**:
* **T1: Commonsense Reasoning**: Question: "Which of the following is the largest planet in our solar system? A) Earth B) Mars C) Jupiter D) Venus?" Answer: C.
* **T2: Mathematical Reasoning**: Question: "Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?" Answer: 72.
* **T3: Code Generation**: Question: "Write a Python function that takes two integers as input and returns their sum." Answer: `def add_numbers(a, b): return a + b`
**Correction Strategies (Top Right)**:
* **S1: Intrinsic Correction**:
* A "Base LLM" provides a "Response" that is reviewed by the "Feedback LLM". The "Generated Feedback" is used to refine the initial "Base LLM" into a "Refine LLM".
* Feedback is internally generated, with visual icons suggesting positive/negative feedback (check mark, smile, neutral, frown).
* **S2: External Correction**:
* Similar structure to S1.
* Includes a "Search Engine" and "Code Executor" which are used to provide "Extra Data Flow" for the "Generated Feedback." This feedback is used to refine the initial "Base LLM" into a "Refine LLM".
* The "Search Engine" box has a search bar labeled "Search..." inside it.
* The "Code Executor" has an icon resembling a computer with code on the screen.
* **S3: Fine-tuned Correction**:
* A "Base LLM" provides a "Response" that is reviewed by the "Feedback LLM". Then a "Fine-tuning" is performed, using a "Fine-tuned Refine LLM". Then "Generated Feedback" is used to refine the initial "Base LLM".
**Model Types (Bottom)**:
* **M1: Instruction-based LLM**: Includes logos for Meta, Qwen, Claude, and OpenAI.
* **M2: Reasoning LLM**: Includes logos for QwQ-32B and deepseek.
### Key Observations
* The diagram clearly distinguishes between methods for improving LLM performance through intrinsic, external, and fine-tuned corrections.
* The separation of instruction-based and reasoning LLMs suggests different architectural and training approaches.
* The presence of "extra data flow" in external correction highlights the use of external tools like search engines and code executors to enhance the feedback process.
### Interpretation
The diagram illustrates the evolution and sophistication of techniques used to improve LLMs. Instruction-based LLMs, represented by prominent industry players like Meta and OpenAI, benefit from correction strategies that involve internal feedback loops, external knowledge sources, and fine-tuning mechanisms. Reasoning LLMs, represented by QwQ-32B and deepseek, are presented as a distinct category, implicitly suggesting they may employ different core architectures or training paradigms that emphasize reasoning capabilities from the outset.
The progression from intrinsic to external to fine-tuned correction indicates a move towards more complex and resource-intensive methods for improving LLM performance. The external correction strategy, in particular, highlights the importance of leveraging external tools and data to ground LLM responses in real-world knowledge. The process appears cyclical, which suggests a closed-loop adaptive system that learns and improves over time.